2.1. Structural Elements 2.1.1. Document Elements 2.1.2. Music Element 2.2. Shared Musical Elements 2.2.1. Score and Parts 2.2.2. Staves and Layers 2.2.3. Basic Music Events 2.2.4. Other events 2.2.5. Expression Marks 2.3. Common Attributes 2.4. User-defined Symbols 2.4.1. Overview of the User Symbols Module 2.4.2. Uses of the Usersymbols Module 2.4.3. Positioning and Coordinates 2.4.4. Line Rendition 2.4.5. Limitations 9.2.2. Text Rendition
2. Shared Concepts in MEI
This chapter describes the elements, models, and attributes that are part of the MEI.shared module. The shared module contains declarations that are common to two or more other modules.
2.1. Structural Elements
2.1.1. Document Elements
Typically, the following elements are available for the representation of the outermost structure of an MEI document:
A typical MEI document contains an mei element, which in turn contains metadata, represented by an meiHead element, and the musical text itself, represented by a music element. The meiHead element, formally declared in the MEI.header module, is described in chapter Structure of the MEI Header.
Other variations on this basic form are also available for the representation of:
- a collection of related MEI-encoded texts, each with its own metadata, known as a corpus;
- a document that contains only metadata, known as an independent or stand-alone header;
- music notation markup without metadata, typically intended to be embedded within another kind of markup, such as TEI.
Further information regarding the organization and encoding of music corpora is given in chapter Musical Corpora. Stand-alone headers are more fully described in chapter Independent Headers.
Inclusion of MEI encodings (partial or complete) inside Text Encoding Initiative (TEI) documents is covered in the TEI Guidelines at http://www.tei-c.org/release/doc/tei-p5-doc/en/html/FT.html#FTNM and by the TEI Music Special Interest Group at http://www.tei-c.org/SIG/Music/twm/index.html.
2.1.2. Music Element
MEI texts may be regarded either as unitary; that is, forming an organic whole, or as composite; that is, consisting of several components which are in some important sense independent of each other. The distinction is not always entirely obvious. For example, a collection of songs might be regarded as a single item in some circumstances, or as a number of distinct items in others. In such borderline cases, the encoder must choose whether to treat the text as unitary or composite; each option may have advantages and disadvantages.
Whether unitary or composite, the musical text is marked with the music tag and may contain front matter, a body, and back matter. In unitary texts, the body is tagged using the body element; in composite texts, however, where the textual body consists of a series of subordinate musical texts or other groups, it is tagged with the group element. The overall structure of any musical text, unitary or composite, is thus defined by the following elements:
Critical editions and collections of works often contain extensive text, such as a title page, table of contents, an introductory essay, commentary, biographical sketch, index, etc. These textual items may appear in either the front or back elements. The front and back elements, available only when the MEI.text module is activated, are described more fully in chapter Text in MEI.
The overall structure of a single musical text is:
<mei>
<meiHead>
<!-- metadata goes here -->
</meiHead>
<music>
<front>
<!-- front matter of text, if any, goes here -->
</front>
<body>
<!-- body of text goes here -->
</body>
<back>
<!-- back matter of text, if any, goes here -->
</back>
</music>
</mei>The top-level structure of a composite musical text made up of two unitary musical texts is:
<mei>
<meiHead>
<!-- metadata for the composite musical text -->
</meiHead>
<music>
<front>
<!-- front matter for composite musical text -->
</front>
<group>
<music>
<front>
<!-- front matter of first unitary musical text, if any -->
</front>
<body>
<!-- body of first unitary musical text -->
</body>
<back>
<!-- back matter of first unitary musical text, if any -->
</back>
</music>
<music>
<body>
<!-- body of second unitary musical text -->
</body>
</music>
</group>
<back>
<!-- back matter for composite musical text, if any -->
</back>
</music>
</mei>2.1.2.1. Grouped Texts
The group element may be used to represent a collection of independent musical texts which is to be regarded as a single unit for processing or other purposes. It is provided to simplify the encoding of collections, anthologies, and cyclic works. It can also be used to record the potentially complex internal structure of corpora, covered more fully in chapter Musical Corpora.
Examples of composite texts which may be represented using the group element include anthologies and other collections. The presence of common front matter referring to the whole collection, possibly in addition to front matter relating to each individual musical text, is a good indication that a given musical text might usefully be encoded in this way.
For example, the overall structure of a collection of songs might be encoded as follows:
<music>
<group>
<music>
<!-- song 1 -->
</music>
<music>
<!-- song 2 -->
</music>
<!-- additional songs here -->
</group>
</music>A group of musical texts may contain other unitary and grouped texts:
<music>
<group>
<music>
<!-- song 1 -->
</music>
<group>
<!-- songs sharing one or more characteristics, treated as a group -->
<music>
<!-- song 2 -->
</music>
<music>
<!-- song 3 -->
</music>
</group>
</group>
</music>The group element may be used to encode any kind of collection in which the constituents are regarded by the encoder as works in their own right, such as ad hoc single- or multiple-composer collections or anthologies of works not originally conceived of as a single composition.
2.1.2.2. Divisions of the Body
This section describes sub-division of the body of a musical text. Front and back matter are described in chapter Text in MEI.
The body of a unitary musical text may contain one or more discrete, linear segments. The names commonly used for these structural subdivisions vary with the genre, style, and time period of the music, or even at the whim of the author, editor, or publisher. For example, a major subdivision of a symphony is generally referred to as a ‘movement’. An opera, on the other hand, is usually organized into ‘acts’ and then further by ‘scenes’. All such divisions are treated as occurrences of the same neutrally-named element, with a @type attribute used to categorize them independently of their hierarchic level.
The following element is used to identify musical subdivisions. As a member of the class att.typed, the mdiv element has attributes which can be used to classify it according to a two-tier hierarchy.
To accommodate “divisions within divisions”, an mdiv element may contain additional mdiv sub-elements nested to any level required. For example, the encoding of a multi-movement work, such as a symphony, frequently have the following structure:
<body xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<mdiv type="symphony">
<mdiv n="1" type="movement">
<!-- contents of mvt 1 -->
</mdiv>
<mdiv n="2" type="movement">
<!-- contents of mvt 2 -->
</mdiv>
<mdiv n="3" type="movement">
<!-- contents of mvt 3 -->
</mdiv>
<mdiv n="4" type="movement">
<!-- contents of mvt 4 -->
</mdiv>
</mdiv>
</body>while dramatic works, such as Verdi’s opera, Il Trovatore, often exhibit a more deeply-nested structure:
<body>
<mdiv type="opera">
<mdiv n="I" type="act">
<mdiv n="1" type="scene">
<!-- contents of act I, sc. 1 -->
</mdiv>
<mdiv n="2" type="scene">
<!-- contents of act I, sc. 2-->
</mdiv>
<mdiv n="3" type="scene">
<!-- contents of act I, sc. 3 -->
</mdiv>
</mdiv>
<mdiv n="II" type="act">
<mdiv n="1" type="scene">
<!-- contents of act II, sc. 1 -->
</mdiv>
<mdiv n="2" type="scene">
<!-- contents of act II, sc. 2 -->
</mdiv>
<mdiv n="3" type="scene">
<!-- contents of act II, sc. 3 -->
</mdiv>
<mdiv n="4" type="scene">
<!-- contents of act II, sc. 4 -->
</mdiv>
<mdiv n="5" type="scene">
<!-- contents of act II, sc. 5 -->
</mdiv>
</mdiv>
<mdiv n="III" type="act">
<mdiv n="1" type="scene">
<!-- contents of act III, sc. 1 -->
</mdiv>
<mdiv n="2" type="scene">
<!-- contents of act III, sc. 2 -->
</mdiv>
<mdiv n="3" type="scene">
<!-- contents of act III, sc. 3 -->
</mdiv>
</mdiv>
<mdiv n="IV" type="act">
<mdiv n="1" type="scene">
<!-- contents of act IV, sc. 1 -->
</mdiv>
<mdiv n="2" type="scene">
<!-- contents of act IV, sc. 2 -->
</mdiv>
<mdiv n="3" type="scene">
<!-- contents of act IV, sc. 3 -->
</mdiv>
</mdiv>
</mdiv>
</body>Conventionally, in performance the musical structures represented by mdiv elements are separated by pauses; however, attacca, attacca subito, seque, or similar terms are sometimes used at the end of an mdiv to indicate that the next mdiv should begin immediately after the conclusion of the current one. These terms have no effect, however, on the logical segmentation of musical content using mdiv elements.
2.1.2.3. Content of Musical Divisions
The mdiv element may contain one or both of two possible views: score and parts.
The score element represents notation in which all the parts of an ensemble are arranged on vertically aligned staves, while the parts element collects the individually notated parts for each performer or group of performers. The explicit encoding of these two ‘views’ is necessary because it is not always possible or desirable to automatically derive one view from the other. In addition, separating scores and parts can eliminate a great deal of markup complexity.
<body>
<mdiv n="1" type="movement">
<score>
<!-- markup of score goes here -->
</score>
<parts>
<!-- markup of performers’ parts goes here -->
</parts>
</mdiv>
<!-- additional movements go here -->
</body>The score and parts elements may also be employed to accommodate different methods of organizing the markup – with no particular presentation implied. In this case, software may render a collection of parts as a score or a score as a collection of parts.
Within the collective parts element, notation for a single performer is represented by the part element:
A part is effectively a small-scale score, allowing all the encoding features of a full score, such as multiple staves, performance directives, and so on. A group of part element is useful for encoding performing parts when there is no score, such as in early music part books; when the parts have non-aligning bar lines; when different layout features, such as page turns, are needed for the score and parts; or for accommodating software that requires part-by-part encoding.
Please note that part elements in MEI are not an indication of voice leading or staff grouping. Voice leading can be encoded using the @next attribute, available on all the members of the model.eventLike class. The staffGrp element handles grouping of staves in the score context.
<parts>
<part label="Violin 1">
<!-- first performer’s part -->
</part>
<part label="Violin 2">
<!-- second performer’s part -->
</part>
<!-- additional performers’ parts -->
</parts>In both score and part views, the scoreDef element is used to describe logical characteristics of the encoded music, such as key signature, the sounding key (as opposed to the notated key signature), meter, etc., and visual features, such as page size, staff groupings and display labels, etc. The staffGrp elements within scoreDef and the order of staffDef elements inside staffGrp should follow the score order of the source for the encoding.
A part or score may be further divided into linear segments called “sections”.
section elements are often used as a scoping mechanism for clef signs, key and meter signatures, as well as metronome, tempo, and expression markings. Using section elements can help to minimize the need for backward scanning to establish context when the starting point for access is not at the beginning of the score. section elements may also be used for other user-defined, i.e., analytical or editorial, purposes and may therefore be arbitrarily nested to any desired level.
The ending element shares the same model as the section element. Unlike section, however, it may not be recursively nested.
The most common (non-analytical, non-editorial) use of section and ending elements is illustrated below:
<music>
<body>
<mdiv>
<score>
<section>
<!-- section one to be repeated -->
</section>
<ending n="1">
<!-- 1st ending -->
</ending>
<ending n="2">
<!-- 2nd ending -->
</ending>
<section>
<!-- next section -->
</section>
</score>
</mdiv>
</body>
</music>Within section elements, several methods of organization are possible, depending upon the notational style of the source material and the encoder’s needs. For example, when the MEI.cmn module is used, the default organization is measure-by-measure, with staff and layer sub-elements within each measure. Further discussion of CMN notation is continued in chapter Repertoire: Common Music Notation.
However, staff-by-staff organization is more appropriate for music without measures and is provided when either the MEI.mensural or MEI.neumes module is employed. Coverage of mensural notation is provided in chapter Repertoire: Mensural Notation, while Repertoire: Neume Notation describes neumatic notation.
It must be noted that, when both the MEI.cmn and MEI.mensural modules are available, it is possible to encode CMN notation without using measure elements; that is, staff-by-staff organization may be used and the ends of measures marked using barLine elements.
In certain circumstances, this approach may be preferable for reproduction of the visual layout of the music. However, the simultaneous use of the
measure and barLine elements may lead to confusion and should be avoided.
Typically, MEI follows the order of sections as they appear in the document being encoded. When performance requires a different order, for instance in the case of D.C. and D.S. directives, the following element may be used to define the performance order.
In the following example, expansion is used to indicate how the notated sections should be ordered in a “through-composed” rendition, for example for machine performance or analysis. The plist attribute contains an ordered list of identifiers of descendant section, ending, lem, or rdg elements. The sequence of values in the plist attribute indicates that the section labelled ‘A’ comes first, then the section labelled ‘B’, followed by the ‘A’ section again. This mechanism must be specified independently of any textual directives, such as “Da capo” or “D.S. al Fine”, that may be present in the document.
<music>
<body>
<mdiv>
<score>
<section>
<expansion plist="#shared.A #shared.B #shared.A"></expansion>
<section xml:id="shared.A">
<!-- "A" section -->
</section>
<section xml:id="shared.B">
<!-- "B" section -->
</section>
</section>
</score>
</mdiv>
</body>
</music>2.2. Shared Musical Elements
This section lists the elements defined in the shared module that are available within the music element.
2.2.1. Score and Parts
The following elements are provided for the capture of scores and parts:
The character of elements specifying one or more score or staff parameters, such as meter and key signature, clefs, etc., is that of a milestone; that is, they affect all subsequent material until a following redefinition. A scoreDef element, which may affect more than just one staff, is allowed only within score, part and section elements, whereas staffDef is allowed only within staffGrp, staff and layer. A staffDef nested inside a staff must bear the same value for its @n attribute as its parent staff and may thus not affect other staves.
The actual use of these elements depends on the repertoire and historical context of the source material. For details on their use in Common Western Notation, please refer to chapter Defining Score Parameters for CMN.
2.2.2. Staves and Layers
The elements below are used to capture the logical organization of musical notation:
The actual use of the staff and layer elements depends on the repertoire and historical context of the source material. For details on their use in Common Western Notation, please refer to chapter The Role of the Measure Element. For mensural notation, see chapter Music Data Organization, and for neumatic notation, chapter Repertoire: Neume Notation.
2.2.3. Basic Music Events
The basic features of music notation are represented by the following elements:
The characteristics of stems on notes and chords are indicated by means of attributes found in the att.stems class.
2.2.4. Other events
Because they can occur in the context of a stream of events on the staff, some elements which are used in other contexts are also treated as events. For example, in addition to being used to define the initial clef of a staff, the clef element can also be used to indicate a clef change.
2.2.4.1. Key Signatures and Clefs
Key signatures and clefs as well as intra-staff changes to these musical parameters are treated as events.
2.2.4.2. Bar Lines and Custos Signs
Measure separators, i.e., bar lines, and custos signs are also considered to be events.
2.2.4.3. Accidentals, Articulation Symbols, Augmentation Dots, and Custos Signs
The following elements are regarded as events primarily because they sometimes occur independently of any associated notes, rests, or chords, especially in mensural and neume repertoires.
2.2.4.4. Lyric Syllables
The syl element is used to mark a word or portion of a word that is to be vocally performed. A fuller description of its use is provided in chapter Lyric Syllables.
2.2.4.5. Event Spacing
The following elements provide control over the horizontal spacing of notational events, such as notes, chords, rests, etc.:
In this context, the term ‘space’ is used to mean whitespace that is required to meaningfully align multiple voices in a multi-voice texture. In DARMS these were referred to as ‘push codes’. The space element is most often used when a new voice appears on a staff mid-measure.
The space element may also be used to align material that crosses staves.
‘Space’ can be thought of as another kind of event. In fact, some refer to this concept as an ‘invisible rest’.
While ‘space’ is meaningful, ‘padding’ is non-essential whitespace that is used to shift the position of the events which follow.
The pad element is provided in order to capture software-dependent placement information when it is desirable to do so. Unless the MEI file will be used as an intermediate file format, this is usually not necessary.
2.2.5. Expression Marks
Expression marks are instructions in the form of words, abbreviations, or symbols that convey aspects of performance that cannot be expressed purely through the musical notation.
2.2.5.1. Text Directives
All of the following elements can be considered text directives; however, MEI uses the dir element specifically for words, abbreviations, numbers, or symbols specifying or suggesting the manner of performance that are not encoded elsewhere using the more specific elements of tempo and dynam.
Examples of directives include text strings such as ‘affettuoso’, fingering numbers, or music symbols such as segno and coda symbols or fermatas over a bar line. Directives can be control elements. That is, they can linked via their attributes to other events. The starting point of the directive may be indicated by either a tstamp, tstamp.ges, tstamp.real or startid attribute, while the ending point may be recorded by either a tstamp2, dur, dur.ges or endid attribute. It is a semantic error not to specify a starting point attribute.
2.2.5.2. Tempo
Tempo marks are indications through words, abbreviations, or specific metronome settings of the speed at which a piece of music is to be performed. Both instantaneous and continuous tempo markings may be encoded using this element.
2.2.5.3. Dynamics
Dynamics, or dynamic marks, are terms, abbreviations, and symbols that indicate the specific degrees of volume of a note, phrase, or section of music, e.g., “piano”, “forte”. Transitions from one volume level to another, e.g., “crescendo”, “diminuendo”, are also specified through dynamic marks.
2.2.5.4. Phrase Marks
Phrase marks are curved lines placed over or under notes to delineate short sections of a work that represent a unified melodic idea, analogous to a phrase in literature.
MEI maintains a distinction between phrase marks and slurs, the latter being curved lines over or under a sequence of notes indicating they are to be performed using a particular playing/singing technique, notes that should be taken in a single breath by wind instruments or played by string instruments using a single stroke of the bow. Often, a slur also indicates that the affected notes should be played in a legato manner.
Even so, it is common for both of these concepts to be referred to generically as “slurs”. Therefore, unless one is encoding music from a repertoire in which this distinction is important, the slur element should be preferred over phrase.
2.2.5.5. Ornaments
Ornaments are formulae of embellishment that can be realized by adding supplementary notes to one or more notes of the melody.
MEI provides a generic element for encoding an ornament symbol that is not a mordent, turn, or trill. For those common CMN ornaments, please refer to Common Music Notation Ornaments.
Ornaments can be represented as textual strings (e.g. with a Unicode symbol) or with a user defined symbol. Ornaments can be control elements. That is, they be can linked via their attributes to other events. It is a semantic error not to specify a starting point attribute with either @tstamp or @startid.
2.3. Common Attributes
The following attributes, provided by the att.common attribute class, are available on nearly all elements in an MEI encoding. They provide the means to identify, label, and access elements in MEI-encoded files.
The value of the @xml:id attribute serves as an identifier for an element and its content. Its value must be unique in the context of the current document and must conform to the definition of an XML Name provided by the W3C Recommendation at http://www.w3.org/TR/xml/#NT-Name. Suggestions for constructing an ID value can be found at http://www.w3.org/TR/xml/#sec-suggested-names.
The @xml:id attribute may take values similar to the following:
<!-- The following are all valid IDs. --><note xml:id="n1"></note>
<note xml:id="_n1"></note>
<note xml:id="thisIsMyFavoriteNote"></note>
<note xml:id="shared.thisIsMyFavoriteNote"></note>This is an example of an incorrectly-formulated @xml:id value:
<!-- xml:id not valid as IDs are not allowed to start with a number. --><note xml:id="1"></note>The @label and @n attributes both serve a labeling function; however, they differ in the values they allow. The @n attribute must be a single token, while @label may contain a string value that includes spaces. This makes @label useful for the capture of free-text labels, but a name or number specified with @n may be easier to process.
<!-- Example of a @label containing whitespace: --><mdiv label="Allegro moderato">…</mdiv>
<!-- Example of a processable @n attribute: -->
<measure n="42">
<!--…-->
</measure>When a reference to an external entity is not a complete URI, the @xml:base attribute can record a value against which it can be resolved into a complete, or absolute, location.
<graphic target="myImage.jpg" xml:base="http://www.mySite.org/images/"></graphic>The value of @xml:base can be inherited from an ancestor. In the following example, the values of the graphic elements’ @target attribute can be completed by the xml:base value specified for the facsimile element:
<facsimile xml:base="http://www.mySite.org/images/">
<surface>
<graphic target="myImage.jpg"></graphic>
<graphic target="myImage.tif"></graphic>
</surface>
</facsimile>See http://www.w3.org/TR/xmlbase/ for more details on xml:base.
2.4. User-defined Symbols
This chapter describes the elements, model classes, and attribute classes that are part of the MEI.usersymbols module.
2.4.1. Overview of the User Symbols Module
The module described in this chapter makes available the following components:
2.4.1.1. Elements
2.4.1.2. Attribute Classes
No attribute classes are defined in this module.
2.4.1.3. Model Classes
The usersymbols module defines the following model classes:
2.4.2. Uses of the Usersymbols Module
The elements provided by the usersymbols module may be used in two ways:
- For defining lines, curves and text elements that cannot be represented by a more specific element.
- For defining reusable symbols and special graphical renditions.
For this purpose, it provides three elements as graphic primitives, line, curve and anchoredText. Anywhere these elements are allowed, the symbol element can be used as well. The symbol element facilitates the re-use of symbols that were defined by symbolDef elements.
2.4.2.1. Defining Reusable Symbols
The symbolDef element uses SVG markup or the aforementioned graphic primitives to describe a symbol. A symbol definition may also use symbols defined by other symbolDef elements by employing the symbol element.
<symbolDef xml:id="userSymbols.triangleSymbol3">
<line x="0" x2="2.55" y="0" y2="4.25"/>
<line x="2.55" x2="5.1" y="4.25" y2="0"/>
<line x="5.1" x2="0.85" y="0" y2="0"/>
</symbolDef>
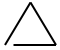
<symbolDef xml:id="userSymbols.triangleSymbolWithStick">
<symbol ref="#userSymbols.triangleSymbol3"/>
<line x="2.55" x2="5.95" y="1.25" y2="3.4"/>
</symbolDef>
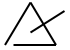
2.4.2.2. Elements Without Semantic Implications
The graphics primitives and symbols can be used directly in the music to describe text and lines on a purely graphical level, without implying a specific logical meaning. If possible, however, more meaningful elements should be used. This means for example, “a tempo” or “da capo” should in general not be put inside anchoredText. Instead, tempo and dir should be used. Likewise, slurs and ties should be encoded using their respective elements, not using curve, and for glissandi, gliss should be used instead of line.
An example usage for line is the visualization of voice leading, which is not covered by a specific MEI element.

<measure n="6">
<staff n="1">
<layer n="1">
<rest dur="4" xml:id="userSymbols.r1"/>
<beam>
<note dur="8" oct="4" pname="c" xml:id="userSymbols.n1"/>
<note dur="8" oct="4" pname="e" xml:id="userSymbols.n2"/>
</beam>
<beam>
<note dur="8" oct="4" pname="g" xml:id="userSymbols.n3"/>
<note dur="8" oct="4" pname="e" xml:id="userSymbols.n4"/>
<note dur="8" oct="4" pname="b" xml:id="userSymbols.n5"/>
<note dur="8" oct="4" pname="g" xml:id="userSymbols.n6"/>
</beam>
<slur curvedir="above" endid="#userSymbols.n6" startid="#userSymbols.n1"/>
</layer>
<layer n="2">
<rest dur="4"/>
<note dur="2" next="#userSymbols.n9" oct="4" pname="c" stem.dir="down" xml:id="userSymbols.n7"/>
</layer>
</staff>
<staff n="2">
<layer n="1">
<note dots="1" dur="2" oct="2" pname="g" xml:id="userSymbols.n8"/>
<note dur="4" oct="3" pname="b" prev="#userSymbols.n7 #userSymbols.n8" xml:id="userSymbols.n9"/>
<slur curvedir="above" endid="#userSymbols.n9" startid="#userSymbols.n8"/>
</layer>
</staff>
<line endid="#userSymbols.n9" rend="dotted" startid="#userSymbols.n7"/>
</measure>
2.4.2.3. Defining a Specific Graphical Rendition for a Semantic Element
Usersymbols can define the rendition of different elements in two ways. Some elements, for example dir and tempo, can have user symbol elements as content. In the following example, the content of dir is used to provide pictograms of percussion instruments.

<section>
<scoreDef meter.count="4" meter.unit="4">
<symbolTable>
<symbolDef xml:id="userSymbols.triangleSymbol1">
<line x="0" x2="2.55" y="0" y2="4.25"/>
<line x="2.55" x2="5.1" y="4.25" y2="0"/>
<line x="5.1" x2="0.85" y="0" y2="0"/>
<line x="2.55" x2="5.95" y="1.25" y2="3.4"/>
</symbolDef>
<symbolDef xml:id="userSymbols.cowbellSymbol">
<line x="1" x2="1.8" y="0" y2="4"/>
<line x="1.8" x2="4.2" y="4" y2="4"/>
<line x="4.2" x2="5" y="4" y2="0"/>
<line x="5" x2="1" y="0" y2="0"/>
<curve bezier="0 1.5 0 1.5" endho="3" endvo="4" startho="1" startvo="4"/>
</symbolDef>
</symbolTable>
<staffGrp>
<staffDef clef.line="2" clef.shape="G" n="1"/>
</staffGrp>
</scoreDef>
<measure n="1">
<staffDef n="1">
<instrDef midi.instrname="Open_Triangle"/>
</staffDef>
<staff n="1">
<layer>
<dir tstamp="1">
<symbol ref="#userSymbols.triangleSymbol2"/>
</dir>
<note dur="1"/>
</layer>
</staff>
</measure>
<measure n="2">
<staffDef n="1">
<instrDef midi.instrname="Cowbell"/>
</staffDef>
<staff n="1">
<layer>
<dir tstamp="1">
<symbol ref="#userSymbols.cowbellSymbol"/>
</dir>
<note dur="4"/>
<note dur="4"/>
<note dur="4"/>
<note dur="4"/>
</layer>
</staff>
</measure>
</section>
A number of elements can point to an internally-defined symbol for rendering using the @altsym attribute.

<scoreDef>
<symbolTable>
<symbolDef xml:id="userSymbols.clefA">
<curve bezier="-1.2 0.1 -0.9 -0.8" endho="1.1" endvo="6.6" startho="1.2" startvo="4"/>
<curve bezier="1 0.9 0.1 1.6" endho="3" endvo="5.3" startho="1.1" startvo="6.6"/>
<curve bezier="-0.1 -2.6 0 2.3" endho="0.6" endvo="-0.1" startho="3" startvo=" 5.3"/>
<curve bezier="0.07 -1.3 -0.2 -1.63" endho="2.4" endvo="0.23" startho="0.6" startvo="-0.1"/>
<curve bezier="0.2 1.3 0.5 0.62" endho="0.8" endvo="0.81" startho="2.4" startvo="0.23"/>
</symbolDef>
<symbolDef xml:id="userSymbols.clefB">
<curve bezier="-0.7 0.1 0.3 0.92" endho="0.7" endvo="-0.2" startho="2.5" startvo=" 1.3 "/>
<curve bezier="-0.27 -0.76 -1.25 -1.26" endho="2" endvo="-0.74" startho="0.7" startvo="-0.2"/>
<curve bezier="1.4 1.8 0.4 -1" endho="1.6" endvo="4.36" startho="2" startvo="-0.74"/>
<curve bezier="-0.89 2.2 -1.1 1.6" endho="3.5" endvo="6.06" startho="1.6" startvo="4.36"/>
<curve bezier="0.8 -1.2 0 0" endho="3.7" endvo="2.66" startho="3.5" startvo="6.06"/>
</symbolDef>
</symbolTable>
<staffGrp>
<staffDef n="1">
<clef altsym="#userSymbols.clefA" line="2" shape="G"/>
</staffDef>
<staffDef n="2">
<clef altsym="#userSymbols.clefB" line="2" shape="G"/>
</staffDef>
</staffGrp>
</scoreDef>
Externally-defined symbols may be referenced using a @glyph.name or @glyph.num attribute from the att.extSym attribute class. Both attributes refer to Standard Music Font Layout (SMuFL) characters, if not specified differently by the @glyph.auth and @glyph.uri attributes.
<ornam tstamp="1">
<symbol glyph.auth="smufl" glyph.num="#xE5C0" glyph.name="ornamentPrecompDoubleCadenceLowerPrefix"/>
</ornam>
2.4.3. Positioning and Coordinates
2.4.3.1. Axis Orientation
MEI uses the classic axis directions where the x-axis points from left to right and the y-axis points from bottom up. (This is compatible with PostScript’s axis orientation, while SVG’s y-axis points in the opposite direction.)
2.4.3.2. Units
There are two types of units used by MEI: Staff units (data.MEASUREMENT) and units of the output coordinate system. Units of the output coordinate system can be translated to physical real world distances by means of the @vu.height and @page.scale of a scoreDef element. Real world units are multiplied by the value of @page.scale to get the corresponding value in output coordinate units.
If an element is scaled using the @scale attribute, the actual size of the units changes accordingly.
2.4.3.3. Positioning
An element may be positioned using either absolute or relative coordinates. If absolute start point coordinates are specified using @x/@y coordinates (or their relatives @x2/@y2 for endpoints) they take precedence over relative positions specified by @ho/@vo/@to (or @startho/@startvo/@startto). Analogously, @x2/@y2 override @endho@endvo/@endto.
If @to/@startto/@endto attributes are used, the start or end point is x-aligned with the indicated timestamp.
If relative start coordinates (@ho/@vo or @startho/@startvo) are used, the origin of the coordinate system to be used for the start point is the first one found by the following search schema:
- If @startid is present, the origin of the referenced element;
- If the element is inside running text (e.g. inside tempo), the end of the preceding text or element;
- Otherwise, the origin of the containing element.
The start point is offset from this origin by the value of the start coordinates (@ho/@vo or @startho/@startvo), using staff units.
Analogously, the endpoint is determined using end coordinates (@endho/@endvo). If @endid is specified, it takes precedence over @startid.
Examples of origins are:
- staff and layer: The horizontal origin is the starting point of the measure, the vertical one is the bottom staff line;
- note: The horizontal origin is the left end of the notehead, the vertical one the center of the notehead;
- clef: The horizontal origin is the left end of the clef, the vertical one the line specified by clef/@line (or @clef.line);
- For elements containing text: The left end of the baseline;
- symbolDef: As symbol definitions aren’t rendered directly, their coordinate system and origin are considered virtual.
When they are referenced by symbol or @altsym, the origin of the context, i.e. the referencing symbol, is used. If neither absolute nor relative coordinates are specified, determining visually suitable start and end points for @line and @curve attributes is left to the rendering application. A value of 0 is not always assumed for absent relative coordinates. A typical example where a rendering application may not choose the origins of absent relative start and end coordinates to be the start point as well is the line connecting two notes in the above Schumann example.
2.4.3.4. Curve Shape
If neither a @bezier nor @bulge attribute is present, the renderer determines a suitable shape. However, if @curvedir is present, the curve must respect the curvature direction specified there.
The attributes @bezier and @bulge define the shape of a curve in two different ways. If both are present, a rendering application may choose either one. They override @curvedir.
@bezier defines the inner control points of a cubic Bézier curve, i.e., a Bézier curve with two inner control points. The coordinates are given by a space separated list, first x and y offsets for the first control point, then x and y offsets for the second one. The x and y offsets are given in staff units (or inside the context of symbolDef in abstract units). The offsets for the first inner control point are relative to the start point, the ones for the second inner control point are relative to the end point.
The @bulge attribute allows specification of the curve shape by a number of interpolation points. The interpolation points are given by their distance from the line connecting the start and end point. The distance values are stored as a space separated list.
The interpolation points are calculated as follows: If @bulge provides n distance values, the connection line is divided into n+1 subsegments of equal length. The interpolation points are found by drawing a perpendicular line of the respective length at each subsegment joint. Positive distance values are drawn to the left of the connection line (left when traveling from start to end), negative ones to the right.
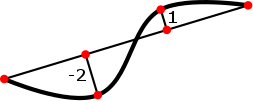
The interpolation algorithm used by the rendering application is implementation dependent.
2.4.4. Line Rendition
The @form attribute of lines may take the following values:
- dashed
- dotted
- solid
- wavy
These attribute values are only qualitative. Actual dash length and dot and dash spacing are implementation dependent.
The @width attribute may take the following values:
- narrow
- medium
- wide
These values are also qualitative, however, they are also relative. That is, ‘narrow’ is the default value, ‘medium’ is twice as wide as ‘narrow’, and ‘wide’ is twice as wide as ‘medium’.
In addition to these textual values, the width attribute may contain a numeric value and an optional unit value, “2mm” for example. If the unit value is not provided, staff interline units are presumed.
The @lstartsym and @lendsym attributes name the symbol that may start and/or end a line, while @lstartsymsize and @lendsymsize indicate the relative size of the symbol using a numeric value in the range from 1 to 9.
2.4.5. Limitations
The usersymbols module does not currently support continuous composite lines or filled areas. As mentioned above, the rendition of lines is highly implementation dependent. Coordinate system transforms are restricted to scaling using @scale.