3.1. Introduction 3.2. Structure of the MEI Header 3.3. Common Metadata Concepts 3.3.1. Title Statement 3.3.2. Responsility Attribution 3.4. Information about an MEI file 3.4.1. File Description 3.4.2. Encoding Description 3.4.3. Revision Description 3.5. Functional Requirements for Bibliographic Records (FRBR) 3.5.1. FRBR Entities in MEI 3.5.2. Component Parts in FRBR 3.5.3. FRBR Relationships 3.5.4. RelatedItem vs. FRBR 3.6. Work Description 3.6.1. Work Identification 3.6.2. Incipits 3.6.3. Key, Tempo, and Meter 3.6.4. Other Identifying Characteristics 3.6.5. Work History 3.6.6. Language Usage 3.6.7. Performance Medium 3.6.8. Audience and Context 3.6.9. Work Contents 3.6.10. Bibliographic Evidence 3.6.11. Notes Statement 3.6.12. Classification 3.6.13. Work Relationships 3.7. Encoding Sources in MEI 3.7.1. Title Pages 3.7.2. Description of folia 3.8. Typical Use Cases 3.8.1. Independent Headers 3.8.2. Including non-MEI Metadata in MEI files 3.8.3. Minimal and Recommended Header Information 3.8.4. Header Elements and their Relationship to Other Bibliographic Standards 3.8.5. Musical Corpora
3. Metadata in MEI
3.1. Introduction
Metadata means “data about data”, i.e. information about various aspects of an encoding at hand. There are many different types of metadata, which MEI tries to order according to their respective scope or perspective, as described in Structure of the MEI Header. MEI’s approach to metadata is heavily influenced by other existing standards and models, such as TEI, MARC, and FRBR. It attempts to reflect both current library practice and common scholarly methods, for example in the field of source descriptions (see chapter Encoding Sources in MEI).
This chapter thus addresses the description of an encoded item so that the musical text, as well as its sources, encoding, and revisions are all thoroughly documented. Such documentation is necessary for scholars using the texts, for software processing them, and for catalogers in libraries and archives. Together these descriptions and declarations provide an electronic analog to the title page attached to a printed work. They also constitute an equivalent for the content of the code books or introductory manuals customarily accompanying electronic data sets.
3.2. Structure of the MEI Header
Every MEI-conformant text not embedded in another XML carrier that provides for capturing metadata, such as TEI or METS, must carry a set of descriptions, prefixed to it and encoded as described in this chapter. This set is known as the MEI header, tagged meiHead.
The metadata encoded inside meiHead covers a number of different use cases. Some child elements like titleStmt may appear in various places (see Title Statement), so it is important to understand the roles of the different areas of the MEI header. These areas are described following their order of appearance within the meiHead element:
- Zero or more alternative identifiers, tagged with altId, each of which provides an identifying name or number associated with the file. This is just a simple element that helps to preserve other external identifiers for a file, such as database keys.
- A file description, tagged fileDesc, containing a full bibliographic description of the computer file itself. From the information contained here, a user of the encoding should be able to derive a proper bibliographic citation, and a librarian or archivist could use it for creating a catalog entry recording its presence within a library or archive. A titleStmt within fileDesc captures the title of the file, which may be different than the title of the encoded work, or the title given on any of the sources used to generate the file. The term computer file here is to be understood as referring to the whole intellectual entity or document described by the header, even when this is stored in multiple physical operating system files. The file description also includes information about the source or sources from which the electronic document was derived (not to be confused with sources that represent or witness the encoded work in a more general sense; these may be described within the manifestationList element). The MEI elements used to encode the file description are described in section Information about an MEI file.
- An optional encoding description, tagged encodingDesc, which describes the relationship between an electronic text and its source or sources. It allows for detailed description of whether (or how) the text was normalized during transcription, how the encoder resolved ambiguities in the source, what levels of encoding or analysis were applied, and similar matters. The MEI elements used to encode the encoding description are described in section Encoding Description.
- An optional work description or list of the works encoded or described in the file, tagged workList, containing classification and contextual information about the work(s), such as its subject matter, the situation in which it was produced, the individuals described by or participating in producing it, and so forth. Such a work profile is of particular use in highly structured composite texts such as corpora or language collections, where it is often highly desirable to enforce a controlled descriptive vocabulary or to perform retrievals from a body of text in terms of text type or origin. The work description may however be of use in any form of automatic text processing. The MEI elements used to encode the work description are described in section Work Description.
- An optional list of manifestations of the work, tagged manifestationList, containing descriptions of sources (“manifestations” in Functional Requirements for Bibliographic Records (FRBR) terms) that represent or witness the encoded work in some way, regardless of whether the encoding is based on these sources or not; for instance, it is useful for listing all known sources to a particular work in a cataloging project or a critical edition. The MEI elements used to encode the source description are described in section Encoding Sources in MEI.
- Zero or more elements tagged extMeta, containing non-MEI metadata. This concept is covered in section Typical Use Cases.
- A revision history, tagged revisionDesc, which allows the encoder to provide a history of changes made during the development of the electronic text. The revision history is important for version control and for resolving questions about the history of a file. The MEI elements used to encode the revision description are described in section Revision Description.
3.3. Common Metadata Concepts
This chapter introduces data models and markup available in various locations of the MEI header.
3.3.1. Title Statement
The titleStmt element is to capture the title of an MEI file (within a fileDesc element) and the title of any of the relevant manifestations (sources) of the encoded work.
The title statement contains the title given to the electronic work, together with one or more optional statements of responsibility which identify the encoder, editor, author, compiler, or other parties responsible for it:
The title element contains the chief name of the electronic work. Its content takes the form considered appropriate by its creator. The element may be repeated, if the work has more than one title (perhaps in different languages). Where the electronic work is derived from an existing source text, it is strongly recommended that the title for the former should be derived from the latter, but clearly distinguishable from it, for example by the addition of a phrase such as ‘: an electronic transcription’ or ‘a digital edition’. This will distinguish the electronic work from the source text in citations and in catalogs, which contain descriptions of both types of material.
<titleStmt xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<title>Lieder-Album für die Jugend</title>
<title type="subtitle">für Singstimme(n) und Klavier,
<identifier>op. 79</identifier>
</title>
<title type="subtitle">an electronic transcription</title>
</titleStmt>Other alternative titles or subtitles may be encoded in additional title elements with values in the @type attribute that distinguish them from the chief title. Sample values for the @type attribute include: main (main title), subordinate (subtitle, title of part), abbreviated (abbreviated form of title), alternative (alternate title by which the work is also known), translated (translated form of title), uniform (collective title).
The @type attribute is provided for convenience in analyzing titles and processing them according to their type; where such specialized processing is not necessary, there is no need for such analysis, and the entire title, including subtitles and any parallel titles, may be enclosed within a single title element, as in the following example:
<title>Symphony No. 5 in C Minor : an electronic transcription</title>The electronic work will also have an external name (its ‘filename’ or ‘data set name’) or reference number on the computer system where it resides at any time. This name is likely to change frequently, as new copies of the file are made on the computer system. Its form is entirely dependent on the particular computer system in use and thus cannot always easily be transferred from one system to another. Moreover, a given work may be composed of many files. For these reasons, these Guidelines strongly recommend that such names should not be used as the title for any electronic work.
Helpful guidance on the formulation of useful descriptive titles in difficult cases may be found in the Anglo-American Cataloguing Rules (Gorman and Winkler, 1978, chapter 25) or in equivalent national-level bibliographical documentation.
It is important to keep in mind that the titleStmt element provides structured metadata. Preserving the exact rendition of a titlepage is possible using the titlePage element (see Title Pages).
The title of a work is given by using the title element directly, as many other child elements of titleStmt are available on work directly.
3.3.2. Responsibility Attribution
In scholarly work, attribution of responsibility is crucial. For this purpose, MEI offers the respStmt element, which is available in the following contexts:
At a minimum, the creator of the musical text and the creator of the file should be identified. If the bibliographic description is for a corpus, identify the creator of the corpus. Optionally also include the names of others involved in the transcription or elaboration of the text, sponsors, and funding agencies. The name of the person responsible for physical data input need not normally be recorded, unless that person is also intellectually responsible for some aspect of the creation of the file.
In traditional bibliographic practice, those with primary creative responsibility are given special prominence. MEI accommodates this approach by providing responsibility-role elements. For example:
<titleStmt>
<title>Auf dem Hügel sitz ich spähend : an electronic transcription</title>
<composer>Ludwig van Beethoven</composer>
<lyricist>Aloys Jeitteles</lyricist>
</titleStmt>Secondary intellectual responsibility in this case is encoded using respStmt. The respStmt element has two subcomponents: a name element identifying a responsible individual or organization, and a resp element indicating the nature of the responsibility. All names should be stated in the form in which the persons or bodies wish to be publicly cited. This will usually be the fullest form of the name, including first names. No specific recommendations are made at this time as to appropriate content for resp. However, it should make clear the nature of the responsibility.
<titleStmt>
<title>Auf dem Hügel sitz ich spähend : an electronic transcription</title>
<composer>Ludwig van Beethoven</composer>
<lyricist>Aloys Jeitteles</lyricist>
<respStmt>
<resp>Encoded by</resp>
<name>Maja Hartwig</name>
<name>Kristina Richts</name>
</respStmt>
</titleStmt>This method of encoding facilitates exchange of bibliographic data with library catalogs and bibliographic databases as well as applications whose handling of bibliographic data is restricted to traditional responsibility roles. Additional information regarding these responsibility-role elements can be found in chapter Bibliographic Citations and References.
When the MEI.namesdates module is enabled, two additional elements are also permitted within respStmt:
These elements allow for more precise identification of the entity associated with the name than is permitted by the simpler name element. The following example shows how a precise date range can be associated with a personal or corporate name.
<respStmt>
<resp>Machine-readable transcription by:</resp>
<persName enddate="1940-11-06" startdate="1860-01-01">John Doe</persName>
</respStmt>For additional information about corporate and personal names, see chapter Names and Dates.
In addition to, or instead of the resp element, the @role attribute on name, persName, and corpName may be used to capture the nature of responsibility. While resp accommodates capturing the wide variety of text that may occur in responsibility statements, use of the @role attribute provides the possibility of recording a controlled value independently of the textual content of resp.
<respStmt>
<resp>Encoded by</resp>
<corpName role="encoder">Members of the Local Symphony Orchestra</corpName>
</respStmt>Values from the MARC relator code list (http://www.loc.gov/marc/relators/relacode.html) or term list (http://www.loc.gov/marc/relators/relaterm.html) are recommended for @role, where applicable.
Where it is necessary to group responsibilities and names, multiple responsibility statements may be used. For example:
<titleStmt>
<title>Symphony No. 5 in C Minor : an electronic transcription</title>
<respStmt>
<resp>Encoded by</resp>
<persName role="encoder">Joe Encoder</persName>
<persName role="encoder">Jane Decoder</persName>
</respStmt>
<respStmt>
<resp>Images scanned by</resp>
<persName>Ludwig van Ludwig</persName>
</respStmt>
</titleStmt>It is often desirable to mix primary and secondary intellectual responsibility information. Treating all intellectual roles the same way can allow literal transcription of existing responsibility statements and simplify programmatic processing. The following example demonstrates how a responsibility statement may be transcribed using interleaved resp and persName elements:
<titleStmt>
<title>Symphony No. 5 in C Minor : an electronic transcription</title>
<respStmt>
<resp>Composed by:</resp>
<persName role="composer">Ludwig van Beethoven</persName>
<persName role="encoder">Johannes Jones:</persName>
<resp>Machine-readable transcription</resp>
</respStmt>
</titleStmt>However, eliminating explanatory text and relying on standardized values for @role, as in the following example, allows data creation and processing tools of the greatest simplicity.
<titleStmt>
<title>Symphony No. 5 in C Minor : an electronic transcription</title>
<respStmt>
<persName role="composer">Ludwig van Beethoven</persName>
<persName role="editor">Johannes Jones</persName>
</respStmt>
</titleStmt>3.4. Information about an MEI file
3.4.1. File Description
The structure of the bibliographic description of a machine-readable or digital musical text resembles that of a book, an article, or other kinds of textual objects. The file description element of the MEI header has therefore been closely modelled on existing standards in library cataloging; it should thus provide enough information to allow users to give standard bibliographic references to the electronic text, and to allow catalogers to catalog it. Bibliographic citations occurring elsewhere in the header, and in the text itself, are derived from the same model.
The bibliographic description of an electronic musical text should be supplied by the mandatory fileDesc element:
The fileDesc element contains two mandatory and six optional elements, each of which is described in more detail below. These elements are listed below in the order in which they must occur within the fileDesc element.
A complete file description will resemble the following example:
<fileDesc>
<titleStmt>
<!-- title of the resource -->
</titleStmt>
<editionStmt>
<!-- information about the edition of the resource -->
</editionStmt>
<extent>
<!-- description of the size of the resource -->
</extent>
<pubStmt>
<!-- information about the publication and distribution of the resource -->
</pubStmt>
<seriesStmt>
<!-- information about any series to which the resource belongs -->
</seriesStmt>
<notesStmt>
<!-- notes on other aspects of the resource -->
</notesStmt>
<sourceDesc>
<!-- information about the source(s) from which the resource was derived -->
</sourceDesc>
</fileDesc>3.4.1.1. Edition Statement
The editionStmt element is the second component of the fileDesc element, following the mandatory titleStmt. It is optional but recommended when applicable.
It contains elements for identifying the edition and those responsible for it:
For printed texts, the term ‘edition’ applies to the set of all the identical copies of an item produced from one master copy and issued by a particular publishing agency or a group of such agencies. A change in the identity of the distributing body or bodies does not normally constitute a change of edition, while a change in the master copy does.
For electronic texts, the notion of a master copy is not entirely appropriate, since they are far more easily copied and modified than printed ones; nonetheless, the term edition may be used for a particular state of a machine-readable text at which substantive changes are made and fixed. Synonymous terms used in these Guidelines are version, level, and release. The words revision and update, by contrast, are used for minor changes to a file which do not amount to a new edition.
No simple rule can specify how substantive changes have to be before they are regarded as producing a new edition, rather than a simple update. The general principle proposed here is that the production of a new edition entails a significant change in the intellectual content of the file, rather than its encoding or appearance. The addition of analytic coding to a text would thus constitute a new edition, while automatic conversion from one coded representation to another would not. Changes relating to the character code or physical storage details, corrections of misspellings, simple changes in the arrangement of the contents and changes in the output format do not normally constitute a new edition, whereas the addition of new information (e.g., annotations, sound or images, links to external data) almost always does.
Clearly, there will always be borderline cases and the matter is somewhat arbitrary. The simplest rule is: if you think that your file is a new edition, then call it such. An edition statement is optional for the first release of a computer file; it is mandatory for each later release, though this requirement cannot be enforced.
Note that all changes in a file, whether or not they are regarded as constituting a new edition or simply a revision, should be independently noted in the revision description section of the file header (see section Revision Description).
The edition element should contain phrases describing the edition or version, including the word ‘edition’, ‘version’, or an equivalent term, together with a number or date, or terms indicating difference from other editions such as ‘new edition’, ‘revised edition’, etc. Any dates that occur within the edition statement should be marked with the date element. The @n attribute of the edition element may be used as elsewhere to supply any formal identification (such as a version number) for the edition.
One or more respStmt elements may also be used to supply statements of responsibility for the edition in question. These may refer to individuals or corporate bodies and can indicate functions such as that of a reviser, or can name the person or body responsible for the provision of supplementary matter, of appendices, etc., in a new edition.
Some examples follow:
<editionStmt>
<edition n="Draft2">Second draft, substantially extended, revised, and corrected.</edition>
</editionStmt><editionStmt>
<edition>Student’s edition,
<date>June 1987</date>
</edition>
<respStmt>
<resp>New annotations by</resp>
<name>George Brown</name>
</respStmt>
</editionStmt>3.4.1.2. Physical Description of the File
The third component of the fileDesc is a description of the physical qualities of the file. The extent element is provided for this purpose.
The extent element describes the approximate size of a text as stored on some carrier medium, whether digital or non-digital, specified in any convenient units.
For printed books, information about the carrier, such as the kind of medium used and its size, are of great importance in cataloging procedures. The print-oriented rules for bibliographic description of an item’s medium and extent need some re-interpretation when applied to electronic media. An electronic file exists as a distinct entity quite independently of its carrier and remains the same intellectual object whether it is stored as file on a hard disc drive, a CD-ROM, a set of USB devices, or in the internet. Since, moreover, these Guidelines are specifically aimed at facilitating transparent document storage and interchange, any purely machine-dependent information should be irrelevant as far as the file header is concerned.
This is particularly true of information about file-type although library-oriented rules for cataloging often distinguish two types of computer file: ‘data’ and ‘programs’. This distinction is quite difficult to draw in some cases, for example, hypermedia or texts with built-in search and retrieval software.
Although it is equally system-dependent, some measure of the size of the computer file may be of use for cataloging and other practical purposes. Because the measurement and expression of file size is fraught with difficulties, only very general recommendations are possible; the element extent should contain a phrase indicating the size or approximate size of the computer file in one of the following ways:
- in bytes of a specified length (e.g. ‘4000 bytes’)
- as falling within a range of values, for example:
- less than 1 Mb
- between 1 Mb and 5 Mb
- between 6 Mb and 10 Mb
- over 10 Mb
- in terms of any convenient logical units (for example, words or sentences, citations, paragraphs)
- in terms of any convenient physical units (for example, compact discs, removable hard drives, DVDs)
The use of standard abbreviations for units of quantity is recommended where applicable, here as elsewhere (see http://physics.nist.gov/cuu/Units/binary.html).
<physDesc>
<extent>between 1 MB and 2 MB</extent>
<extent>4.2 MiB</extent>
<extent>4532 Mbytes</extent>
<extent>3200 sentences</extent>
<extent>5 90-mm high density diskettes</extent>
</physDesc>For ease of processability, the use of the @unit attribute is recommended whenever possible, as in the following example:
<extent unit="byte">65535</extent>The @unit attribute is restricted to certain values: “byte” (Byte), “char” (Character), “cm” (Centimeter), “deg” (Degree), “in” (Inch), “issue” (Serial issue), “ft” (Foot), “m” (Meter), “mm” (Millimeter), “page” (Page), “pc” (Pica), “pt” (Point), “px” (Pixel), “rad” (Radian), “record” (Record), “vol” (Serial volume), and “vu” (MEI virtual unit).
3.4.1.3. Publication, Distribution, etc.
The pubStmt element is the fourth component of the fileDesc element and is mandatory.
It may contain either a single unpub element, indicating that the file has yet to be published, or in the case of published material, one or more elements from the model.pubStmtPart class. The following elements may be used to provide details regarding the file’s publication and distribution:
The publisher is the person or institution by whose authority a given edition of the file is made public. The distributor is the person or institution from whom copies of the text may be obtained. Use respStmt to identify other responsible persons or corporate bodies.
The sub-elements of availability should be used to provide detailed information regarding access to the MEI file.
<pubStmt xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<publisher>
<corpName>Musikwissenschaftliches Seminar <Detmold></corpName>
</publisher>
<address>
<addrLine>Gartenstrasse 20</addrLine>
<addrLine>32756
<geogName>Detmold</geogName>
</addrLine>
<addrLine>
<geogName>Germany</geogName>
</addrLine>
</address>
<date>2011</date>
<availability>
<useRestrict>© 2004, MEI Consortium</useRestrict>
</availability>
</pubStmt><pubStmt xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<publisher>
<corpName>Segno Press Inc.</corpName>
</publisher>
<distributor>
<corpName>University of Virginia</corpName>
<address>
<addrLine>221 B LowWater Street,</addrLine>
<addrLine>Charlottesville, Virginia</addrLine>
<addrLine>22901</addrLine>
</address>
</distributor>
<date>2010</date>
<identifier>1234</identifier>
<availability>
<useRestrict>Available for purposes of academic research and teaching only.</useRestrict>
</availability>
</pubStmt>Give any other useful information (e.g., dates of collection of data) in an annotation within the notes statement, which is described below.
Here, as in the description of intellectual responsibility described above, the respStmt element may be used to contain all statements of responsibility regarding publication and distribution when uniformity is desired regardless of the role of participants in the publication process:
<respStmt xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<corpName role="publisher">MEI Project</corpName>
<corpName auth.uri="http://d-nb.info/gnd" auth="GND" codedval="2007744-0" role="funder">German Research Foundation</corpName>
<corpName auth.uri="http://d-nb.info/gnd/18183-3" auth="Deutsche Nationalbibliothek" codedval="18183-3" role="funder">National Endowment for the Humanities</corpName>
</respStmt>3.4.1.4. Series Statement
The seriesStmt element is the fifth component of the fileDesc element and is optional.
A series may be defined in one of the following ways:
- A group of separate items related to one another by the fact that each item bears, in addition to its own title proper, a collective title applying to the group as a whole. The individual items may or may not be numbered.
- Each of two or more volumes of essays, lectures, articles, or other items, similar in character and issued in sequence.
- A separately numbered sequence of volumes within a series or serial.
The seriesStmt element may contain one or more of the following more specific elements:
The title, editor and identifier elements have the same function described above: identification of the item, in this case the series, and the individuals or groups responsible for its creation. The title element is required within seriesStmt.
<seriesStmt>
<title>MEI Sample Collection</title>
</seriesStmt>The identifier element may be used to supply any identifying number associated with the series, including both standard numbers such as an ISSN and particular issue numbers. Its @type attribute is used to categorize the number further, taking the value ‘ISSN’ for an ISSN, for example.
<seriesStmt>
<title level="s">Studies in Ornamentation</title>
<editor>Jacques Composeur</editor>
<identifier type="ISSN">0-345-6789</identifier>
</seriesStmt>The contents of the series may be enumerated using the contents element. Use of this element should be determined by the complexity of the resource and whether or not the information is readily available. The contents element may consist of a single paragraph when unstructured information is sufficient.
<contents>
<p>On Wenlock Edge -- From Far, From Eve and Morning -- Is My Team Ploughing? -- Oh,
When I Was In Love With You -- Bredon Hill -- Clun
</p>
</contents>Alternatively, contentItem elements may be used to provide structure for the content description.
<contents>
<head>Contents</head>
<contentItem>On Wenlock Edge</contentItem>
<contentItem>From Far, From Eve and Morning</contentItem>
<contentItem>Is My Team Ploughing?</contentItem>
<contentItem>Oh, When I Was In Love With You</contentItem>
<contentItem>Bredon Hill</contentItem>
<contentItem>Clun</contentItem>
</contents>Finally, using the @target attribute, a link to an external table of contents may be supplied in lieu of or in addition to the child elements of contents.
<contents target="http://www.series.content/12345"></contents>The seriesStmt element is allowed to nest within itself in order to accommodate a series within a series.
3.4.1.5. Notes Statement
The notesStmt element is the sixth component of the fileDesc element and is optional. If used, it contains one or more annot elements, each containing a single piece of descriptive information of the kind treated as ‘general notes’ in traditional bibliographic descriptions.
Some information found in the notes area in conventional bibliography has been assigned specific elements in these Guidelines; in particular the following items should be tagged as indicated, rather than as general notes:
- the nature, scope, artistic form, or purpose of the work; also the genre or other intellectual category to which it may belong. These should be formally described within the workList element (section Work Description).
- bibliographic details relating to the source or sources of an electronic text: e.g., ‘Transcribed from a facsimile of the 1743 publication’. These should be formally described in the sourceDesc element (section Source Description).
- further information relating to publication, distribution, or release of the text, including sources from which the text may be obtained, any restrictions on its use or formal terms on its availability. These should be placed in the appropriate division of the pubStmt element (section Publication, Distribution, etc.).
- publicly documented numbers associated with the file should be placed in an altId element within the meiHead element. International Standard Serial Numbers (ISSN), International Standard Book Numbers (ISBN), and other internationally agreed upon standard numbers that uniquely identify an item, should be treated in the same way, rather than as specialized bibliographic notes. As described elsewhere, identifiers for sources of the file should be recorded within the sourceDesc.
Nevertheless, the notesStmt element may be used to record potentially significant details about the file and its features, for example:
- dates, when they are relevant to the content or condition of the computer file: e.g. ‘manual dated 2010’, ‘file validated Apr 2011’
- names of persons or bodies connected with the technical production, administration, or consulting functions of the effort which produced the file, if these are not named in statements of responsibility in the title or edition statements of the file description: e.g. ‘Historical commentary provided by members of the Big Symphony Orchestra’
- availability of the file in an additional medium or information not already recorded about the availability of documentation: e.g. ‘User manual is loose-leaf in eleven paginated sections’
- language of work and abstract, if not encoded in the langUsage element, e.g. ‘Text in English with stage directions in French and German’
Each such item of information may be tagged using the general-purpose annot element. Groups of annotations are contained within the notesStmt element, as in the following example:
<notesStmt>
<annot>Historical commentary provided by John Smith.</annot>
<annot>OCR scanning performed at University of Virginia.</annot>
</notesStmt>There are advantages, however, to encoding such information with more precise elements elsewhere in the MEI header, when such elements are available. For example, the notes above might be encoded as follows:
<titleStmt>
<title>…</title>
<respStmt>
<persName>John Smith</persName>
<resp>historical commentary</resp>
</respStmt>
<respStmt>
<corpName>University of Virginia</corpName>
<resp>OCR scanning</resp>
</respStmt>
</titleStmt>3.4.1.6. Source Description
The sourceDesc element is the seventh and final component of the fileDesc element. In MEI, sourceDesc is a grouping element containing one or more source elements, each of which records details of a source from which the computer file is derived. This might be a printed text or manuscript, another computer file, an audio or video recording, or a combination of these. An electronic file may also have no source, if what is being cataloged is an original text created in electronic form.
The source element may contain
3.4.1.6.1. Associating Metadata and Data
In the MEI header, the @data attribute may be used to associate metadata with related notational elements.
Similarly, in the body of the MEI document, the @decls attribute may be used to associate parts of the encoded text with related metadata.
The most useful associations of this type are between the bibliographic description of a source and the material taken from it.
3.4.2. Encoding Description
The encodingDesc element is the second major subdivision of the MEI header. It specifies the methods and editorial principles which governed the transcription or encoding of the source material. Though not formally required, its use is highly recommended.
The encoding description may contain elements taken from the model.encodingPart class. By default, this class makes available the following elements:
Each of these elements is further described in the appropriate section below.
3.4.2.1. Application Information
It is sometimes convenient to store information relating to the processing of an encoded resource within its header. Typical uses for such information might be:
- to allow an application to discover that it has previously opened or edited a file, and what version of itself was used to do that;
- to show (through a date) which application last edited the file to allow for diagnosis of any problems that might have been caused by that application;
- to allow users to discover information about an application used to edit the file
-
to allow the application to declare an interest in elements of the file which it has edited, so that other applications or human editors may be more wary of making changes to those sections of the file.
Provides information about an application which has acted upon the current document.
</div>
Each application element identifies the current state of one software application with regard to the current file. This element is a member of the att.datable class, which provides a variety of attributes for associating this state with a date and time, or a temporal range. The @xml:id and @version attributes should be used to uniquely identify the application and its major version number (for example, ‘Music Markup Tool 1.5’). It is not intended that a software application should add a new application element each time it touches the file.
The following example shows how these elements might be used to record the fact that version 1.5 of an application called ‘Music Markup Tool’ has an interest in two parts of a document. The parts concerned are accessible at the URLs given as targets of the two ptr elements. When used on application, the @date attribute specifies when the application was employed, in this case June 6, 2011. Version information for the application should be placed in @version.
<appInfo>
<application isodate="2011-06-06" version="1.5" xml:id="header.MusicMarkupTool">
<name>Music Markup Tool</name>
<ptr target="#header.P1"></ptr>
<ptr target="#header.P2"></ptr>
</application>
</appInfo>3.4.2.2. Declaration of Editorial Principles
The editorialDecl element is used to provide details of the editorial practices applied during the encoding of a musical text.
It may contain a prose description only, or one or more of a set of specialized elements; that is, members of the MEI model.editorialDeclPart class.
Some of these policy elements carry attributes to support automated processing of certain well-defined editorial decisions; all of them contain a prose description of the editorial principles adopted with respect to the particular feature concerned. Examples of the kinds of questions which these descriptions are intended to answer are given in the list below.
correction: correctionStates how and under what circumstances corrections have been made in the text. corrlevelIndicates the degree of correction applied to the text. methodIndicates the method employed to mark corrections and normalizations. Was the text corrected during or after data capture? If so, were corrections made silently or are they marked using the tags described in chapter 11 Editorial Markup? What principles have been adopted with respect to omissions, truncations, dubious corrections, alternate readings, false starts, repetitions, etc.?
interpretation: interpretationDescribes the scope of any analytic or interpretive information added to the transcription of the music. Has any analytic or ‘interpretive’ information been provided — that is, information which is felt to be non-obvious, or potentially contentious? If so, how was it generated? How was it encoded?
normalization: normalizationIndicates the extent of normalization or regularization of the original source carried out in converting it to electronic form. methodIndicates the method employed to mark corrections and normalizations. Was the text normalized, for example by regularizing any non-standard enharmonic spellings, etc.? If so, were normalizations performed silently or are they marked using the tags described in chapter 11 Editorial Markup ? What authority was used for the regularization? Also, what principles were used when normalizing numbers to provide the standard values for the value attribute described in section 1.3.4 Names, Dates, Numbers, Abbreviations, and Addresses and what format is used for them?
segmentation: segmentationDescribes the principles according to which the musical text has been segmented, for example into movements, sections, etc. How is the musical text segmented? If mdiv and/or section elements have been used to partition the music for analysis, how are they marked and how was the segmentation arrived at?
standard values: stdVals(standard values) – Specifies the format used when standardized date or number values are supplied. In most cases, attributes bearing standardized values should conform to a defineddatatype. In cases where this is not appropriate, this element may be used to describe the standardization methods underlying the values supplied.
Experience shows that a full record should be kept of decisions relating to editorial principles and encoding practice, both for future users of the text and for the project which produced the text in the first instance. Any information about the editorial principles applied not falling under one of the above headings may be recorded as additional prose following the special-use elements.
<editorialDecl>
<segmentation>
<p>Separate mdiv elements have been created for each movement of the work.</p>
</segmentation>
<interpretation>
<p>The harmonic analysis applied throughout movement 1 was added by hand and has not
been checked.
</p>
</interpretation>
<correction>
<p>Errors in transcription controlled by using the Finale editor.</p>
</correction>
<normalization>
<p>All sung text converted to Modern American spelling following Webster’s 9th Collegiate
dictionary.
</p>
</normalization>
<p>
<!-- Other editorial practices described here. -->
</p>
</editorialDecl>An editorial practices declaration which applies to more than one text or division of a text need not be repeated in the header of each text or division. Instead, the @decls attribute of each text (or subdivision of the text) to which it applies may be used to supply a cross-reference to a single declaration encoded in the header.
3.4.2.3. Project Description
The projectDesc element may be used to describe, in prose, the purpose for which a digital resource was created, together with any other relevant information concerning the process by which it was assembled or collected. This is of particular importance for corpora or miscellaneous collections, but may be of use for any text, for example to explain why one kind of encoding practice has been followed rather than another.
For example:
<encodingDesc>
<projectDesc>
<p>Texts collected for use in the MEI Summer Workshop, Aug. 2012.</p>
</projectDesc>
</encodingDesc>3.4.2.4. Sampling Declaration
The samplingDecl element holds a prose description of the rationale and methods used in selecting texts, or parts of text, for inclusion in the resource.
The samplingDecl element should include information about such matters as:
- the size of individual samples
- the method or methods by which they were selected
- the underlying population being sampled
- the object of the sampling procedure used but is not restricted to these.
<samplingDecl>
<p>Encoding contains 40 randomly-selected measures.</p>
</samplingDecl>It may also include a simple description of any parts of the source text included or excluded:
<samplingDecl>
<p>Only the songs have been transcribed. Advertisements have been silently omitted. All
mathematical expressions have been omitted, and their place marked with a
<gi scheme="MEI">gap</gi>element.
</p>
</samplingDecl><samplingDecl>
<p>Only the first 6 measures of movement 1 are encoded.</p>
</samplingDecl>A sampling declaration which applies to more than one text or division of a text need not be repeated in the header of each such text. Instead, the @decls attribute of each text (or subdivision of the text) to which the sampling declaration applies may be used to supply a cross-reference to it, as further described in section Associating Metadata and Data.
3.4.2.5. Class Declarations
The classDecls element allows the declaration of generic taxonomies for the classification of entities according to one or both of the following two methods:
- by reference to a recognized international classification scheme such as the Dewey Decimal Classification, the Universal Decimal Classification, the Colon Classification, the Library of Congress Classification, or any other system widely used in library and documentation work
-
by providing a set of keywords, as provided, for example, by British Library or Library of Congress Cataloguing in Publication data, or as defined by the encoder.
Groups information which describes the nature or topic of an entity.
</div>
Each taxonomy may have a heading and may declare any number of categories using the category element. Categories may be declared by reference to existing vocabularies or simply explained by a descriptive text.
<classDecls>
<taxonomy>
<head>Subject categories</head>
<category xml:id="header.LoC_lcco">
<desc>Library of Congress subject headings. Prepared by the Cataloging
Policy and Support Office, Collections Services. Washington, D.C.:
Library of Congress, Cataloging Distribution Service, 1993- . </desc>
</category>
</taxonomy>
</classDecls>The category element may or may not include a bibliographic citation and/or a URI at which the classification scheme or information about it may be found.
<taxonomy>
<category auth.uri="http://www.loc.gov" auth="Library of Congress" xml:id="header.LCSH"/>
<category auth.uri="http://www.loc.gov/aba/cataloging/classification/lcco/lcco_m.pdf" xml:id="header.LoC_lcco">
<desc>Library of Congress subject headings. Prepared by the Cataloging Policy and Support
Office, Collections Services. Washington, D.C.: Library of Congress, Cataloging Distribution
Service, 1993- .</desc>
</category>
</taxonomy>The categories declared in the taxonomies may then be referenced to within classification by means of the @class attribute as described in the headerWorkClass section.
3.4.3. Revision Description
The final sub-element of the MEI header, the revisionDesc element, provides a detailed change log in which each change made to a text may be recorded. Its use is optional but highly recommended. It provides essential information for the administration of large numbers of files which are being updated, corrected, or otherwise modified as well as extremely useful documentation for files being passed from researcher to researcher or system to system. Without change logs, it is easy to confuse different versions of a file, or to remain unaware of small but important changes made in the file by some earlier link in the chain of distribution. No change should be made in any MEI-conformant file without corresponding entries being made in the change log.
The main purpose of the revision description is to record changes in the text to which a header is prefixed. However, it is recommended practice to include entries also for significant changes in the header itself (other than the revision description itself, of course). At the very least, an entry should be supplied indicating the date of creation of the header.
The log consists of a list of change elements, each of which contains a detailed description of the changes made. If a number is to be associated with one or more changes (for example, a revision number), the @n attribute may be used to indicate it. The person responsible for the change and the date of the change may be indicated by the respStmt and date elements. The description of the change itself is contained within the changeDesc element, which can hold one or more paragraphs.
It is recommended to give changes in reverse chronological order, most recent first.
For example:
<revisionDesc>
<change n="4">
<respStmt>
<persName>KR</persName>
</respStmt>
<changeDesc>
<p>Cleaned up MEI file automatically using Header.xsl.</p>
</changeDesc>
<date isodate="2011-12-01"></date>
</change>
<change n="3">
<respStmt>
<persName>KR</persName>
</respStmt>
<changeDesc>
<p>Cleaned up MEI file automatically using ppq.xsl.</p>
</changeDesc>
<date isodate="2011-10-21"></date>
</change>
</revisionDesc>A slightly shorter form for recording changes is also available when a the date of the change can be described by a single date in a standard ISO form and when the name of the agent(s) responsible for the change, encoded elsewhere in the header, can be referred to by one or more URIs given in the @resp attribute. For example:
<change isodate="2011-10-21" n="3" resp="#KR #MH">
<changeDesc>
<p>Cleaned up MEI file automatically using ppq.xsl.</p>
</changeDesc>
</change>3.5. Functional Requirements for Bibliographic Records (FRBR)
MEI header information may refer to different levels of description of the encoded work: Some information may apply the work in all its various forms and realizations, e.g., the name of its composer. Other information may describe a certain version of the work, or a source such as the printed first edition, or only a single copy of that source. Core MEI limits the header information to two such levels of description: work and source, respectively.
However, when the FRBR module is available more detailed descriptions are possible. With certain limitations, mainly due to the musical nature of the works encoded in MEI, the FRBR module adapts the Functional Requirements for Bibliographic Records (FRBR) as recommended by the International Federation of Library Associations and Institutions (IFLA) [http://www.ifla.org/publications/functional-requirements-for-bibliographic-records].
The IFLA’s FRBR model distinguishes four levels of abstraction, or entities:
Work: FRBR defines a work as a “distinct intellectual or artistic creation”, an abstract entity because there is no single material object one can point to as the work.
Expression: An expression is defined as “the intellectual or artistic realization of a work in the form of […] notation, sound, image, object, movement, etc., or any combination of such forms”. Expressions are also abstract entities.
Manifestation: A manifestation is defined as “the physical embodiment of an expression of a work”, including, for instance, manuscripts, books, sound recordings, films, video recordings, CD-ROMs, multimedia kits, etc. The manifestation represents all the physical objects that bear the same characteristics, with respect to both intellectual content and physical form.
Item: A single exemplar of a manifestation is called an item, e.g., a specific copy of a printed score. With manuscripts, item and manifestation levels are nearly identical. A manuscript may be regarded as a manifestation having only one item.
3.5.1. FRBR Entities in MEI
With the FRBR module, MEI offers four elements corresponding to the FRBR “Group 1” entities:
The names of the MEI entities follow those of FRBR: the work element is a container for description at the FRBR “work” level, expression is for description at the FRBR “expression” level, manifestation contains “manifestation” level description, and item holds FRBR “item” level description. Please note: Until MEI 3.0.0, the source element in sourceDesc was used for manifestation-level descriptions.
The work element has an optional child element to hold the expression elements:
As expressionList is a container element for descriptions of different expressions of the same work, it may contain only
expression elements.
The content model of expression is similar to that of work. It does not, however, permit expressionList and audience elements. But it adds elements that aid identification and description of specific versions of a work:
Since expressions, like works, are abstractions, their titles are often nebulous. Usually, however, the title of an expression is the same as the work it represents. When the relationship between a work and an expression is encoded hierarchically, the expression’s title element may be omitted with the assumption that it will be inherited from the work. If no title is provided for an expression, distinguishing characteristics must be provided in other elements, such as perfMedium, as in the following example:
<work xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<title>Pavane pour une infante défunte</title>
<expressionList>
<expression>
<title/>
<perfMedium>
<perfResList>
<perfRes>piano</perfRes>
</perfResList>
</perfMedium>
</expression>
<expression>
<title/>
<perfMedium>
<perfResList>
<perfRes>orchestra</perfRes>
</perfResList>
</perfMedium>
</expression>
</expressionList>
</work>Programmatic concatenation of the work title and one or more characteristics of the expression can be used to provide identification for the expression. For example, the expressions above may be identified by “Pavane pour une infante défunte (piano)” and “Pavane pour une infante défunte (orchestra)”. In some cases, it may be helpful to assign a descriptive title to the expression, as illustrated below. The carrier of the manifestation is often a good source of this kind of descriptive text.
<work xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<title>Pavane pour une infante défunte</title>
<expressionList>
<expression>
<title>Version for piano</title>
<perfMedium>
<perfResList>
<perfRes>piano</perfRes>
</perfResList>
</perfMedium>
</expression>
<expression>
<title>Version for orchestra</title>
<perfMedium>
<perfResList>
<perfRes>orchestra</perfRes>
</perfResList>
</perfMedium>
</expression>
</expressionList>
</work><work xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<title>Sonata No. 2</title>
<expressionList>
<expression>
<title>Live recording at Carnegie Hall</title>
</expression>
<expression>
<title>Studio recording</title>
</expression>
</expressionList>
</work>The itemList element provides functionality similar to that of expressionList; that is, it can be used to group descriptions of individual items (exemplars) of the parent source. Just like expressionList, which can only hold expression sub-components, itemList may only contain item elements.
<manifestation xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<titleStmt>
<title>Trois trios pour le piano-forte violon, et violoncelle</title>
</titleStmt>
<itemList>
<item label="Copy at Stanford">
<physLoc>
<repository>
<corpName>Stanford University Library</corpName>
</repository>
</physLoc>
</item>
<item label="Copy at Dresden">
<physLoc>
<repository>
<corpName>Dresden, Sächsische Landesbibliothek - Staats- und Universitätsbibliothek</corpName>
</repository>
</physLoc>
</item>
</itemList>
</manifestation>3.5.2. Component Parts in FRBR
Each of the four MEI elements corresponding to FRBR entities may contain a list of constituent parts. All four entities utilize the same element:
However, the child elements of a component group must be the same type as the group’s parent. This allows for a more detailed description than is possible using the core MEI contents element. For example, a work element’s componentList element can only contain work elements, etc. In this way, the componentList element may be employed to describe composite works, as in the example below:
<work xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<title>Der Ring des Nibelungen</title>
<componentList>
<work>
<title>Das Rheingold</title>
</work>
<work>
<title>Die Walküre</title>
</work>
<work>
<title>Siegfried</title>
</work>
<work>
<title>Götterdämmerung</title>
</work>
</componentList>
</work>This technique can also be applied when a single intellectual source is comprised of multiple physical parts. In the following example, the choral parts were published in four physically separate “signatures”:
<manifestation xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron" xml:id="source.printed_choral_parts">
<titleStmt>
<title>Printed choral parts</title>
</titleStmt>
<pubStmt>
<publisher>Horneman & Erslev</publisher>
<pubPlace>Copenhagen</pubPlace>
<date isodate="1871">1871</date>
</pubStmt>
<componentList>
<manifestation>
<titleStmt>
<title>Soprani</title>
</titleStmt>
<physDesc>
<extent unit="pages">4</extent>
</physDesc>
</manifestation>
<manifestation>
<titleStmt>
<title>Alti</title>
</titleStmt>
<physDesc>
<extent unit="pages">4</extent>
</physDesc>
</manifestation>
<manifestation>
<titleStmt>
<title>Tenori</title>
</titleStmt>
<physDesc>
<extent unit="pages">6</extent>
</physDesc>
</manifestation>
<manifestation>
<titleStmt>
<title>Bassi</title>
</titleStmt>
<physDesc>
<extent unit="pages">6</extent>
</physDesc>
</manifestation>
</componentList>
</manifestation>3.5.3. FRBR Relationships
FRBR defines a number of terms that describe how the basic entities relate to each other. MEI provides the following elements for this purpose.
Each of the four FRBR entity equivalents – the work, expression, source, and item elements – allows a list of such relationship descriptions as its last child element. relationList provides a container for individual relation elements. The nature of the relationship must be specified by the @rel attribute and the target of the relationship must be identified by the @target attribute. The values allowed by @rel follow those defined for FRBR at http://www.ifla.org/files/assets/cataloguing/frbr/frbr_2008.pdf.
Since relations are bidirectional, they may be defined on both entities involved, using pairs of oppositely-directed relation descriptors. The following FRBR relations are allowed in MEI as values of the relation element’s @rel attribute (shown in pairs for clarity):
- hasAbridgement / isAbridgementOf
- hasAdaptation / isAdaptationOf
- hasAlternate / isAlternateOf
- hasArrangement / isArrangementOf
- hasComplement / isComplementOf
- hasEmbodiment / isEmbodimentOf
- hasExemplar / isExemplarOf
- hasImitation / isImitationOf
- hasPart / isPartOf
- hasRealization / isRealizationOf
- hasReconfiguration / isReconfigurationOf
- hasReproduction / isReproductionOf
- hasRevision / isRevisionOf
- hasSuccessor / isSuccessorOf
- hasSummarization / isSummarizationOf
- hasSupplement / isSupplementOf
- hasTransformation / isTransformationOf
- hasTranslation / isTranslationOf
Some of these relationships are already implicitly expressed by the MEI structural model: FRBR defines an expression entity as a realization of a work, but as this relation is implied by the expressionList element’s child relationship to its parent work element, the hasRealization/isRealizationOf relation does not need to be explicitly declared. Likewise, it is not necessary to specify by means of relation elements that an item is an exemplar of the source described by its parent source element. This resembles the FRBR model, which allows 1:n relationships both between works and expressions, and between manifestations and items.
However, as FRBR allows n:n relations between expressions and manifestations (in MEI: sources), a hierarchical model based on the structure of XML is clearly insufficient to express all possible expression / manifestation combinations. It is therefore required to declare these relations explicitly. In FRBR terms, a manifestation / source is an embodiment of an expression.
<manifestation xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<titleStmt>
<title>Score, first edition</title>
</titleStmt>
<relationList>
<relation rel="isEmbodimentOf" target="#version_for_orchestra"></relation>
</relationList>
</manifestation>Within the componentList element, the order of child elements implicitly describes a hasSuccessor/isSuccessorOf relationship between components, i.e. it defines a certain sequence such as the movements of a work. In other cases, relation elements may be needed to explicitly encode relationships not otherwise defined by encoding order or hierarchy. For instance, the hasReproduction/isReproductionOf relationship may be used to indicate that one source is a reprint of another.
<manifestation xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<pubStmt>
<publisher>Horneman & Erslev</publisher>
<pubPlace>Copenhagen</pubPlace>
<date isodate="1874">1874</date>
</pubStmt>
<relationList>
<relation rel="isReproductionOf" target="#source.printed_choral_parts"></relation>
</relationList>
</manifestation>Moreover, the use of componentList implicitly defines a hasPart/isPartOf relationship between the componentList element’s parent and its child elements. Using the relationList and relation elements to define their relationship, the four component works in the “Der Ring des Nibelungen” example above could alternatively be encoded as sibling work elements to the “Ring” work element.
<workList xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<work xml:id="theRing">
<title>Der Ring des Nibelungen</title>
<relationList>
<relation rel="hasPart" target="#rheingold"></relation>
<relation rel="hasPart" target="#walkuere"></relation>
<relation rel="hasPart" target="#siegfried"></relation>
<relation rel="hasPart" target="#goetterdaemmerung"></relation>
</relationList>
</work>
<work xml:id="rheingold">
<title>Das Rheingold</title>
<relationList>
<relation rel="isPartOf" target="#theRing"></relation>
</relationList>
</work>
<work xml:id="walkuere">
<title>Die Walküre</title>
<relationList>
<relation rel="isPartOf" target="#theRing"></relation>
</relationList>
</work>
<work xml:id="siegfried">
<title>Siegfried</title>
<relationList>
<relation rel="isPartOf" target="#theRing"></relation>
</relationList>
</work>
<work xml:id="goetterdaemmerung">
<title>Götterdämmerung</title>
<relationList>
<relation rel="isPartOf" target="#theRing"></relation>
</relationList>
</work>
</workList>Relations may also be used to point to external resources. For instance, each of the individual component works of the “Ring” could be encoded in separate files, with relations pointing to them.
In the file “ring.xml”:
<workList xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<work>
<title>Der Ring des Nibelungen</title>
<relationList>
<relation rel="hasPart" target="rheingold.xml"></relation>
<relation rel="hasPart" target="walkuere.xml"></relation>
<relation rel="hasPart" target="siegfried.xml"></relation>
<relation rel="hasPart" target="goetterdaemmerung.xml"></relation>
</relationList>
</work>
</workList>In the file “rheingold.xml”:
<workList xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<work>
<title>Das Rheingold</title>
<relationList>
<relation rel="isPartOf" target="ring.xml"></relation>
</relationList>
</work>
</workList>3.5.4. RelatedItem vs. FRBR
MEI offers two related concepts for capturing relations between bibliographic items. The model of relatedItem, as described in chapter Related Items of these Guidelines, is derived from MODS v3.4 (see documentation here). Its purpose in MEI is to encode bibliographic references between mostly “secondary” material, like reviews, articles, and so on. It may be used to provide cross-references between information encoded in different places of the header.
However, relatedItem is less ideal for describing the relations between works, differing versions of these works, the sources in which those versions are transmitted, and where applicable the individual copies of a print. For these situations, it is strongly recommended to use the Functional Requirements for Bibliographic Records (FRBR) instead. This module is based on the Functional Requirements for Bibliographic Records, as specified by the IFLA. It allows a much finer description of relationships between such “primary” entities. For compatibility reasons, both models should not be confused or mixed under any circumstances.
3.6. Work Description
The workList element is the third major subdivision of the MEI Header. It is an optional element, the purpose of which is to enable the recording of information characterizing various descriptive aspects of the abstract work.
Within workList, the work element is used to hold information for each resource being described.
All the components of work are optional, but they must occur in the following order:
- identifier
- title
- Responsibility-like elements including composer, lyricist, contributor and others
- incip
- key
- mensuration
- meter
- tempo
- otherChar
- history
- langUsage
- perfMedium
- audience
- contents
- context
- biblList
- notesStmt
- classification
3.6.1. Work Identification
The following elements provide minimal identifying information for the intellectual work:
The identifier and title values recorded here may or may not be the same as those assigned to published versions of the work. Fuller details are available in section Title Statement.
3.6.2. Incipits
The first few notes and/or words of a piece of music are often used for identification purposes, especially when the piece has only a generic title, such as “Sonata no. 3”. They appear in catalogs of music and in tables of contents of printed music that include multiple works.
The following elements are provided for the inclusion of incipits:
The elements incipCode and incipText are available for the inclusion of coded incipits of music notation and textual incipits, respectively. The incipText element should contain only the initial performed text of the work, while incipCode may contain both words and music, depending on the capabilities of the scheme used to encode it. When both music and text are provided in incipCode, it may be helpful to repeat the text in incipText in order to provide easier access to only the text, for example, for indexing of the text without having to extract it from the coded incipit.
Both incipCode and incipText allow reference to an external file location via the @target attribute and specification of the internet media type of the external file via the @mimetype attribute.
An MEI-encoded incipit may be captured in a score sub-element.
In addition, graphic may be used as a sub-element of incip to include an image of an incipit.
To facilitate the capture of metadata associated with an incipit, MEI allows the following sub-elements within incip. The order of their presentation below follows the order in which they must appear in this context.
Usually, the metadata captured in this manner is rendered alongside or in lieu of a coded or graphical incipit. It may or may not serve in a work identification capacity, depending on whether the incipit is intended to represent the entire work or a segment of the work. For example, if an incipit is provided for each aria in an opera, then the metadata pertains only to the aria, not the entire work.
3.6.3. Key, Tempo, and Meter
The attributes key, tempo, and meter are often helpful for identifying a musical work when it does not have a distinctive title.
The key element is used exclusively within bibliographic descriptions. Do not confuse this element with keySig, which is used within the body of an MEI file to record this data for musical notation. Likewise, meter should not be confused with the attributes used by staffDef and scoreDef to record meter-related data for notated music. The tempo element can be used here as well as in the body of an MEI document; however, its attributes other than @xml:id, @label, @n, @base, and @lang are meaningless in the MEI header context, and therefore should be avoided within a work description. The mensuration element is available for the description of works in the mensural repertoire. When a work uses meter and mensural signs, both mensuration and meter elements may be used.
3.6.4. Other Identifying Characteristics
Additional information that aids the identification of the work may be encoded using otherChar.
The following components provide detailed information about the work’s context, including the circumstances of its creation, the languages used within it, high-level musical attributes, performing forces, etc.
3.6.5. Work History
The following elements are provided to capture the history of a musical work:
The creation element is intended to contain a brief, machine-processable statement of the circumstances of the work’s creation. Its content is limited to text and the date and geogName elements.
The history element is a container for additional non-bibliographic details relating to a work. It may use the eventList element to provide a list of key events in the creation and performance history of the work. The eventList element is comprised of event elements containing a brief description of the associated event, including dates and locations where the event took place. An event list may use the @type attribute to distinguish between multiple event lists with different functions, such as a list of events in the compositional process and a list of performance dates.
Event lists and other text components, such as paragraphs, tables, lists, and text divisions ( div) may be interleaved when an ‘essay-like’ work history is desired.
The event element permits either a text-centric or a data-centric model. The text-centric model is provided for prose descriptions, while the data-centric model accommodates event descriptions that consist of a collection of descriptive phrases. In the text-centric model, paragraphs, tables, and lists may be used. In the data-centric model, however, only certain phrase-level elements, may appear.
3.6.6. Language Usage
The langUsage element is used within the workList element to describe the languages, sublanguages, dialects, etc. represented within a work. It contains one or more language elements, each of which provides information about a single language.
A language element may be supplied for each different language used in a document. If used, its @xml:id attribute should specify an appropriate language identifier. This is particularly important if extended language identifiers have been used as the value of @xml:lang attributes elsewhere in the document.
Here is an example of the use of this element:
<langUsage>
<language xml:id="fr-CA">Québecois</language>
<language xml:id="en-CA">Canadian English</language>
<language xml:id="en-GB">British English</language>
</langUsage>
<!-- Later in the document -->
<verse n="1" xml:lang="fr-CA"></verse>
<verse n="2" xml:lang="en-CA"></verse>
<verse n="3" xml:lang="en-GB"></verse>3.6.7. Performance Medium
The following elements are available for description of a composition’s performing forces:
The perfMedium element provides the possibility of describing a work in terms of its medium of performance; that is, the performing forces required. In the case of a dramatic work, the dramatis personae and associated voice qualities may be enumerated using castList. The perfResList element describes the necessary instrumental and vocal resources.
3.6.7.1. Cast Lists
A cast list is a specialized form of list, conventionally found at the start or end of a dramatic work, usually listing all the speaking/singing and non-speaking/singing roles in the play, often with additional description (‘Cataplasma, a maker of Periwigges and Attires’) or the name of an actor or actress (‘Old Lady Squeamish. Mrs Rutter’).
Cast lists often function as identifying metadata and for this reason are permitted within the description of a work.
Because the format and internal structure of cast lists are unpredictable, a castList may contain any combination of castItem and castGrp elements.
A castItem element may contain any mixture of text and the following elements:
In the following example, role provides the name of the dramatic character and roleDesc contains a brief description of the role. The perfRes element is used to describe the voice range of the role.
<castList xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<castItem>
<role>Ursula</role>
<roleDesc>Queen of the Britons</roleDesc>
<perfRes>Soprano</perfRes>
</castItem>
<castItem>
<role>Dersagrena</role>
<roleDesc>Handmaiden to Ursula</roleDesc>
<perfRes>Mezzo-Soprano</perfRes>
</castItem>
<castItem>
<role>Fingal</role>
<roleDesc>King of the Britons</roleDesc>
<perfRes>Baritone</perfRes>
</castItem>
</castList>The vocal qualities and associated roles for Beethoven’s opera Fidelio may be encoded as:
<perfMedium>
<castList>
<castItem>
<perfRes>Tenor</perfRes>
<role>Florestan</role>
</castItem>
<castItem>
<perfRes>Soprano</perfRes>
<role>Leonore</role>,
<roleDesc>his wife</roleDesc>
</castItem>
<castItem>
<perfRes>Bass</perfRes>
<role>Rocco</role>,
<roleDesc>gaoler</roleDesc>
</castItem>
<castItem>
<perfRes>Soprano</perfRes>
<role>Marzelline</role>,
<roleDesc>his daughter</roleDesc>
</castItem>
<castItem>
<perfRes>Tenor</perfRes>
<role>Jaquino</role>,
<roleDesc>assistant to Rocco</roleDesc>
</castItem>
<castItem>
<perfRes>Bass-baritone</perfRes>
<role>Don Pizarro</role>,
<roleDesc>governor of the prison</roleDesc>
</castItem>
<castItem>
<perfRes>Bass</perfRes>
<role>Don Fernando</role>,
<roleDesc>King’s minister</roleDesc>
</castItem>
</castList>
</perfMedium>The castItem element may also contain:
However, this element is unlikely to be useful in the context of a work description. It may be used here, however, for the very rare occasion when a work was conceived for and is only performable by a single person or group, as for certain “performance art” works.
It is common to find some roles presented in groups or sublists. Roles are also often grouped together by their function. To accommodate these situations, the castGrp element is provided as a component of castList. It may contain any combination of castItem, castGrp, and roleDesc elements.
3.6.7.2. Instrumentation
The perfResList element is used to capture the solo and ensemble instrumental and vocal resources of a composition. For example, a work for a standard ensemble may be indicated thus:
<perfMedium>
<perfResList>
<perfRes>Orchestra</perfRes>
</perfResList>
</perfMedium>The detailed make-up of standard and non-standard ensembles may also be enumerated:
<perfMedium>
<perfResList>
<head>Orchestration</head>
<perfRes>Flute</perfRes>
<perfRes>Oboe</perfRes>
<perfRes>English Horn</perfRes>
<perfRes>2 Horns in D</perfRes>
<perfRes>Strings</perfRes>
</perfResList>
</perfMedium>Where multiple instruments of the same kind are used, the @count attribute on perfRes may be used to encode the exact number of players called for.
<perfMedium>
<perfResList>
<!-- concert band -->
<perfRes count="2">Piccolo</perfRes>
<perfRes count="2">Flute</perfRes>
<perfRes count="3">1st Clarinet</perfRes>
<perfRes count="3">2nd Clarinet</perfRes>
<perfRes count="3">3rd Clarinet</perfRes>
<!-- and so on -->
</perfResList>
</perfMedium>Instrument or voice specifications may be grouped using the perfResList element and a label assigned to the group with
head. For example:
<perfMedium>
<perfResList>
<!-- concert band -->
<perfResList>
<head>Woodwinds</head>
<perfRes count="2">Piccolo</perfRes>
<perfRes count="2">Flute</perfRes>
<perfRes count="3">1st Clarinet</perfRes>
<perfRes count="3">2nd Clarinet</perfRes>
<perfRes count="3">3rd Clarinet</perfRes>
<!-- etc. -->
</perfResList>
<perfResList>
<head>Brass</head>
<perfRes count="3">1st Trumpet</perfRes>
<perfRes count="3">2nd Trumpet</perfRes>
<perfRes count="3">3rd Trumpet</perfRes>
<!-- etc. -->
</perfResList>
<!-- and so on -->
</perfResList>
</perfMedium><perfMedium xmlns="http://www.music-encoding.org/ns/mei" xmlns:rng="http://relaxng.org/ns/structure/1.0" xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<perfResList>
<perfResList>
<head>Woodwinds</head>
<perfRes codedval="wa" count="2">2 Flutes
<perfRes codedval="wz">(2. piccolo)</perfRes>
</perfRes>
<perfRes codedval="wc" count="1">1 Oboe</perfRes>
<!-- ... -->
</perfResList>
<perfResList>
<head>Strings (8-6-4-4-2)</head>
<perfRes count="8">Violin 1</perfRes>
<perfRes count="6">Violin 2</perfRes>
<perfRes count="4">Viola</perfRes>
<perfRes count="4">Violoncello</perfRes>
<perfRes count="2">Double Bass</perfRes>
</perfResList>
</perfResList>
</perfMedium>The preceding example also demonstrates how instrumental doublings can be accommodate through the use of nested perfRes elements. Only the outer-most perfRes element should use the @count attribute. Its value should reflect the total number of performers, not the number of instruments played.
The perfRes element provides the @codedval attribute, which can be used to record a coded value that represents the string value stored as the element’s content. It is recommended that coded values be taken from a standardized list, such as the International Association of Music Libraries’ Medium of Performance Codes List or the MARC Instruments and Voices Code List.
<perfMedium>
<perfResList>
<!-- @codedval contains values from the MARC Instruments and Voices Code List -->
<perfRes codedval="ba">Horn</perfRes>
<perfRes codedval="bb">Trumpet</perfRes>
<perfRes codedval="bd">Trombone</perfRes>
</perfResList>
</perfMedium>Solo parts may be marked with the @solo attribute of perfRes, like so:
<perfResList>
<perfRes solo="true">Violin</perfRes>
<perfRes>Violin</perfRes>
<perfRes>Violin</perfRes>
<perfRes>Viola</perfRes>
<perfRes>Violoncello</perfRes>
</perfResList>Music for a single player should, however, never use the @solo attribute.
<!-- This is an example of what not to do --><perfResList>
<perfRes solo="true">Piano</perfRes>
</perfResList>3.6.8. Audience and Context
The intended audience for the work and additional information about context for the work that is not captured in more specific elements elsewhere, such as history and its sub-components, may be recorded in the audience and context elements.
3.6.9. Work Contents
Often, it is helpful to identify an entity by listing its constituent parts. A simple description of the work’s content, such as may be found in a bibliographic record, can be given in single paragraph element:
<contents>
<p>A suitable tone ; Left hand colouring ; Rhythm and accent ; Tempo ; Flexibility ;
Ornaments
</p>
</contents>Alternatively, a structured list of contents may be constructed using the contentItem element:
<contents>
<contentItem>Sonata in D major, op. V, no. 1 / Corelli</contentItem>
<contentItem>Sonata in G minor / Purcell (with Robert Donington, gamba)</contentItem>
<contentItem>Forlane from Concert royal no. 3 / Couperin</contentItem>
</contents>Each contentItem element may be preceded by an optional label:
<contents>
<label>1</label>
<contentItem>Sonata in D major, op. V, no. 1 / Corelli</contentItem>
<label>2</label>
<contentItem>Sonata in G minor / Purcell (with Robert Donington, gamba)</contentItem>
<label>3</label>
<contentItem>Forlane from Concert royal no. 3 / Couperin</contentItem>
</contents>To reference a contents list in an external location, use the @target attribute:
<contents target="http://www.contentProvider.org/toc/toc01.html"/>To facilitate the creation of music catalogs based on MEI header information, contents may contain a heading:
<contents>
<head>Contents of this Work:</head>
<contentItem>Sonata No. 1</contentItem>
<contentItem>Sonata No. 2</contentItem>
<contentItem>Sonata No. 3</contentItem>
</contents>3.6.10. Bibliographic Evidence
The biblList element allows citation of bibliographic evidence supporting assertions made within other sub-components of the work description.
3.6.11. Notes Statement
The notesStmt element may be used within the description of the musical work to capture information not accounted for by the other elements of the description.
3.6.12. Classification
Within work, the classification element is used to classify the work according to some classification scheme. More generally, classification may be used to classifiy any FRBR entity ( work, expression, manifestation, or item). The following elements are provided for this purpose:
The termList element categorizes the parent entity by supplying a set of terms which may describe its topic or subject matter, its physical or intellectual form, date, etc. Each term is indicated by a term element. In some schemes, the order of items in the list is significant, for example, from major topic to minor; in others, the list has an organized substructure of its own. No recommendations are made here as to which method is to be preferred. Wherever possible, such terms should be taken from a recognized source. In its simplest form, the term element just contains a descriptive keyword.
<termList>
<term>motet</term>
</termList>The @class attribute may be used on each term element to make reference to a classification scheme (declared in the classDecls element) from which it is drawn.
<classification>
<termList>
<term class="#header.LCSH">Guitar music (Rock)</term>
<term class="#header.LCSH">Rock music 1971-1980.</term>
<term class="#header.LoC_lcco">M1630.18.Z26 O6 2011</term>
</termList>
</classification>Alternatively, @class may be used on termList when all the contained terms come from the same source.
<classification>
<termList class="#header.LCSH">
<term>Guitar music (Rock)</term>
<term>Rock music 1971-1980.</term>
</termList>
<termList class="#header.LoC_lcco">
<term>M1630.18.Z26 O6 2011</term>
</termList>
</classification>3.6.13. Work Relationships
When the FRBR (Functional Requirements for Bibliographic Records) module is available, the following elements may be used within work to describe relationships between the work being described and other works or between the work and expressions of it:
For more information about FRBR and the use of these elements, see chapter Functional Requirements for Bibliographic Records (FRBR).
3.7. Encoding Sources in MEI
The
manifestation and
item elements allow detailed description of various types of sources, for instance, a printed text or manuscript, another computer file, an audio or video recording, or a combination of these.
Both
manifestation and
item are part of the
Functional Requirements for Bibliographic Records (FRBR) implementation in MEI.
Please note: in MEI 3.0.0, the
source element was used to capture this type of information.
The
manifestation element may contain the following elements:
The content of the item is quite similar to manifestation with a few omissions:
Many of these elements are already described in chapter 3.1 , especially in 3.1.3 Work Description.
The manifestationList is available to create lists of physical sources representing a work, for instance for use in a thematic catalog or a critical edition. The manifestation child element corresponds to the Functional Requirements for Bibliographic Records (FRBR) level of the same name, that is, it describes embodiments of certain expressions of a work. The list below reflects the order in which the optional components of manifestation must occur.
3.7.1. Title Pages
A specialized element is furnished for the capture of titlepage information.
The titlePage element, modelled after a similar element in Encoded Archival Description (EAD), may occur within the textual matter preceding or following the musical content of the encoding. Since a diplomatic transcription of the titlepage is often necessary to accurately identify musical material contained within a source, titlePage may also be used within the metadata header as a child of the physDesc element.
Detailed analysis of the title page and other preliminaries of older printed books and manuscripts is of major importance in descriptive bibliography and the cataloging of printed books. The following elements are suggested as a means of encoding the major features of most title pages for faithful rendition:
The following example shows the encoding of the title page of Vaughan Williams’ On Wenlock Edge. Note the use of the lb element to mark the line breaks present in the original.
<titlePage>
<p>ON WENLOCK EDGE</p>
<p>A CYCLE OF SIX SONGS<lb/>
FOR TENOR VOICE ___ WITH ACCOMPANIMENT OF<lb/>
Pianoforte and String Quartet (ad lib)<lb/>
THE WORDS BY A. E. HOUSMAN<lb/>
(FROM "A SHROPSHIRE LAD")
</p>
<p>
<fig/>
</p>
<p>MUSIC BY<lb/>
R. VAUGHAN<lb/>
WILLIAMS
</p>
<list>
<li>PRICE $3.75</li>
<li>(COMPLETE WITH SET OF STRING PARTS $5.00</li>
<li>STRING PARTS SEPARATELY $1.00</li>
</list>
<p>Boosey & Hawkes, Inc.</p>
<p>New York, U.S.A.</p>
<p>London · Toronto · Sydney · Capetown</p>
</titlePage>The physical rendition of title page information is often of considerable importance. One approach to this requirement would be to use the rend element, described in chapter Text Rendition to specify the rendition of each of the components of the title page. Another would be to employ a CSS stylesheet. Finally, a module customized for the description of typographic entities such as pages, lines, rules, etc., bearing special-purpose attributes to describe line-height, leading, degree of kerning, font, etc. could be employed.
3.7.2. Description of folia
While many other elements within physDesc describe specific features of manuscripts and prints in prose, foliaDesc is intended to be processable. It provides information about the binding of a manuscript or print and the layout of its pages. The most important elements used are:
The nesting of bifolium and folium elements reflects the nesting of paper sheets that make up the text block of the source. For instance, if a manuscript consists of two folded sheets of paper, with a single, unfolded sheet in the middle, this would be encoded with two nested bifolium elements, where the inner one has an additional folium element:
<foliaDesc>
<bifolium><!-- outer sheet -->
<bifolium><!-- inner sheet -->
<folium/><!-- single leaf in the middle -->
</bifolium>
</bifolium>
</foliaDesc>
Multiple signatures (groups of nested pages) bound together can be reflected by encoding a sequence of bifolium elements (with their respective contents). If the binding of a source is unknown, but foliaDesc is needed for other reasons, it is recommended to use a sequence of folium elements only, with no indication of nesting at all.
3.7.2.1. Linking surface elements
The surface element and it’s children are used to relate musical content with digitizations and specific image zones on them (see Elements of the Facsimile Module). surface elements are always encoded in sequence within facsimile, and thus lack the expressiveness of foliaDesc. However, it is possible to relate these two concepts.
folium offers two specific attributes:
These attributes are used to point to the @xml:id of a surface element.
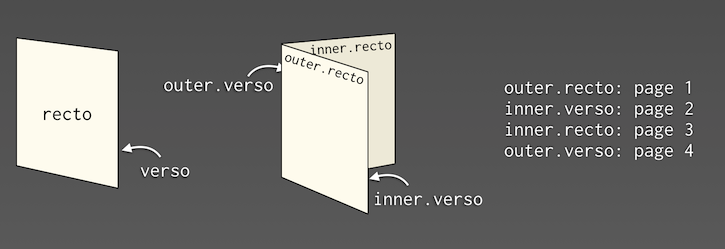
On bifolium, the corresponding attributes are:
With those attributes, page numbers can be derived from foliaDesc, alongside the information where the content on a given surface is placed on a (bi)folium. Coming back to the example above this might look like so:
<foliaDesc>
<bifolium outer.recto="#surface-p1" inner.verso="#surface-p2" inner.recto="#surface-p9" outer.verso="#surface-p10">
<bifolium outer.recto="#surface-p3" inner.verso="#surface-p4" inner.recto="#surface-p7" outer.verso="#surface-p8">
<folium recto="#surface-p5" verso="#surface-p6"/>
</bifolium>
</bifolium>
</foliaDesc>3.7.2.2. Specifying page dimensions
Within surface, each graphic element may specify its dimensions using the following attributes:
The values of those attributes, however, specify the height and width of the digital resource, the scan of the source, and they are typically given in pixels (see Elements of the Facsimile Module). In contrast, folium and bifolium are supposed to provide the dimensions of the original source in cm or inches. This makes it possible to combine separate parts of a manuscripts stored in different libraries, which are scanned at different resolutions. In case of bifolium elements, these dimensions apply to the folded sheet.
Some printed scholarly editions like the Neue Bach-Ausgabe provide very detailed information about the sizes and binding of individual leaves of a manuscript; with foliaDesc and its children it is possible to encode that information in processable ways, even without providing digitizations of the sources via surface.
3.7.2.3. Patches
Sometimes, manuscripts (but also prints) are subject to modifications that do not change the textual content, but the actual physical item. Typical examples for this are patches glued on a page, or cutouts. Both these situations can be encoded inside
foliaDesc.
A patch is an additional writing surface attached to one of the sides of a folium or bifolium:
The patch element is placed inside the folium or bifolium to which it is attached. To which side of this parent it is attached is specified using the (required) @attached.to attribute:
Depending on the parent, allowed values for @attached.to are either “recto” and “verso” (in case of folium) or “outer.recto”, “inner.verso”, “inner.recto” and “outer.verso” (in case of bifolium).
The exact position of the patch on the underlying surface may be specified using the optional @x and @y attributes, which are used to specify the distance from the upper left corner of the patch from the upper left corner of the surface it is attached to. At this point, it is not possible to specify rotation.
The (optional) @attached.by attribute specifies by which means the patch is attached. Suggested values are: “glue” (patch is glued on surface beneath), “thread” (patch is sewn on surface beneath), “needle” (patch is pinned to the surface beneath), “tape” (patch is taped on surface beneath using an adhesive strip) and “staple” (patch is attached on surface beneath using a staple), but other values may be used as necessary.
While the patch element provides information about the attachment of a patch, the actual patch is encoded as a folium or bifolium child of patch.
<bifolium>
<patch attached.to="inner.verso" x="1cm" y="12cm" attached.by="glue">
<folium width="8cm" height="2cm"/>
</patch>
</bifolium>
The example above describes a bifolium where a patch is glued to the inner right side.
3.7.2.4. Cutouts
Cutouts are treated almost similarly as Patches. The most relevant attributes are:
The dimensions (@width, @height) of the parent element (e.g. folium) indicate the size of the bounding box of the remaining part of the page. That is, if the complete lower half of a page has been cut, the @width and @height attributes describe the remaining upper half. If, in contrast, only the lower right quarter of the page has been cut, these attributes still indicate the size of the full page (assuming that the removed section was a regular rectangle).The dimensions (@width, @heigh) on cutout itself are only to be used when there is a “gap” in the manuscript that allows to specify the dimensions of that missing part. In this case, the bounding box dimensions are given, together with @x and @y to indicate the upper left point on the original page. If, however, the removed section is available by itself, then a corresponding folium (or bifolium) should be placed inside the cutout element, and should provide it’s own dimensions using @width and @height there. In this case, @width and @height on cutout is expendable.
The genetic aspect of applying patches or cutting out parts of a page is described in Genetic Markup.
3.8. Typical Use Cases
This chapter introduces common use cases for MEI metadata.
3.8.1. Independent Headers
Many libraries, repositories, research sites and related institutions collect bibliographic and documentary information about machine readable music documents without necessarily collecting the music documents themselves. Such institutions may thus want access to the header of an MEI document without its attached text in order to build catalogs, indexes and databases that can be used to locate relevant texts at remote locations, obtain full documentation about those texts, and learn how to obtain them. This section describes a set of practices by which the metadata headers of MEI documents can be encoded separately from those documents and exchanged as freestanding MEI documents. Headers exchanged independently of the documents they describe are called independent headers.
3.8.1.1. Independent MEI Headers
An independent header is an MEI metadata header that can be exchanged as an independent document between libraries, archives, collections, projects, and individuals.
The structure of an independent header is exactly the same as that of an header attached to a document. This means that an meiHead can be extracted from an MEI document and sent to a receiving institution with little or no change.
When deciding which information to include in the independent header, and the format or structure of that information, the following should be kept in mind:
- The independent header should provide full bibliographic information about the encoded text, its sources, where the text can be located, and any restrictions governing its use.
- The independent header should contain useful information about the encoding of the text itself. In this regard, it is highly recommended that the encoding description be as complete as possible. The Guidelines do not require that the encoding description be included in the header (since some simple transcriptions of small items may not require it), but in practice the use of a header without an encoding description would be severely limited.
- The independent header should be amenable to automatic processing, particularly for loading into databases and for the creation of publications, indexes, and finding aids, without undue editorial intervention on the part of the receiving institution. For this reason, two recommendations are made regarding the format or structure of the header: first, where there is a choice between a prose content model and one that contains a formal series of specialized elements, wherever possible and appropriate the specialized elements should be preferred to unstructured prose. Second, with respect to corpora, information about each of the texts within a corpus should be included in the overall corpus-level meiHead. That is, source information, editorial practices, encoding descriptions, and the like should be included in the relevant sections of the corpus meiHead, with pointers to them from the headers of the individual texts included in the corpus. There are three reasons for this recommendation: first, the corpus-level header will contain the full array of bibliographic and documentary information for each of the texts in a corpus, and thus be of great benefit to remote users, who may have access only to the independent header; second, such a layout is easier for the coder to maintain than searching for information throughout a text; and third, generally speaking, this practice results in greater overall consistency, especially with respect to bibliographic citations.
3.8.2. Including non-MEI Metadata in MEI files
The following element is provided to accommodate non-MEI metadata:
The extMeta element may be contained by expression, item, manifestation, work and meiHead elements. It may include text and any number of well-formed XML fragments, XML comments, and CDATA sections, except for MEI markup, which is prohibited. The document element of each fragment must explicitly declare its namespace.
<extMeta>
<!-- MARC (Machine-Readable Cataloging) title info -->
<datafield xmlns="http://www.loc.gov/MARC21/slim" ind1="1" ind2="0" tag="245">
<subfield code="a">Simple dreams :</subfield>
<subfield code="b">a musical memoir /</subfield>
<subfield code="c">Linda Ronstadt.</subfield>
</datafield>
</extMeta>An MEI processor is not required to validate or otherwise process any markup within the extMeta element. Therefore, the extMeta element itself is the lowest level at which an association can be created between ‘foreign’ metadata and other MEI elements as described in section Associating Metadata and Data.
3.8.3. Minimal and Recommended Header Information
The MEI header allows for the provision of a very large amount of information concerning the text itself, its source, its encodings, and revisions of it, as well as a wealth of descriptive information, such as the languages it uses and the situation(s) in which it was produced, together with the setting and identity of participants within it. This diversity and richness reflects the diversity of uses to which it is envisaged that electronic texts conforming to these Guidelines will be put. It is emphatically not intended that all of the elements described above should be present in every MEI Header.
The amount of encoding in a header will depend both on the nature and the intended use of the text. At one extreme, an encoder may expect that the header will be needed only to provide a bibliographic identification of the text adequate to local needs. At the other, wishing to ensure that their texts can be used for the widest range of applications, encoders will want to document as explicitly as possible both bibliographic and descriptive information, in such a way that no prior or ancillary knowledge about the text is needed in order to process it. The header in such a case will be very full, approximating the kind of documentation often supplied in the form of a manual. Most texts will lie somewhere between these extremes; textual corpora in particular will tend more to the latter extreme. In the remainder of this section we demonstrate first the minimal, and then a commonly recommended, level of encoding for the bibliographic information held by the MEI header.
Supplying only the level of encoding required, the MEI header of a single text will look like the following example:
<meiHead>
<fileDesc>
<titleStmt>
<title>Fughette (in Gottes Namen Fahren wir - Dies sind die heil'gen zehn Gebote) for Brass
Quintett : an electronic transcription
</title>
</titleStmt>
<pubStmt>
<respStmt>
<corpName auth.uri="http://d-nb.info/gnd" auth="GND" codedval="5115204-6">Musikwissenschaftliches Seminar <Detmold></corpName>
</respStmt>
</pubStmt>
</fileDesc>
</meiHead>The only mandatory component of the MEI Header is the fileDesc element. Within this element, titleStmt and pubStmt are required constituents. Within the title statement, a title is required. Within the pubStmt, a publisher, distributor, or other agency responsible for the file is required.
While not formally required, additional information is recommended for a minimally effective header. For example, it is recommended that the person or corporate entity responsible for the creation of the encoding should be specified using respStmt within the titleStmt element. It is also recommended that information about the source, or sources, of the encoding be included. Each source element should contain at the least a loosely structured bibliographic citation that identifies the source used to construct the MEI file.
Furthermore, If the electronic transcription is a member of a series of publications, the series title and publisher should be included using the seriesStmt element. It is also common for cataloging records to include genre and/or form information, here represented by the MEI classification element.
We now present the same example header, expanded to include additionally recommended information, adequate for most bibliographic purposes, in particular to allow for the creation of an AACR2-conformant bibliographic record.
<meiHead>
<fileDesc>
<titleStmt>
<title>Fughette (in Gottes Namen Fahren wir - Dies sind die heil'gen zehn Gebote) for Brass
Quintett : an electronic transcription
</title>
<respStmt>
<resp>Encoded by:</resp>
<persName xml:id="header.MH">Maja Hartwig</persName>
<persName xml:id="header.KR">Kristina Richts</persName>
</respStmt>
</titleStmt>
<pubStmt>
<respStmt>
<corpName>Musikwissenschaftliches Seminar <Detmold></corpName>
</respStmt>
<date>2011</date>
</pubStmt>
<seriesStmt>
<title>MEI Sample Collection</title>
<respStmt>
<corpName role="publisher">MEI Project</corpName>
</respStmt>
</seriesStmt>
<sourceDesc>
<source>
<bibl>
<title>Fughette (in Gottes Namen Fahren wir - Dies sind die heil'gen zehn Gebote) for Brass Quintett</title>
</bibl>
</source>
</sourceDesc>
</fileDesc>
<encodingDesc>
<classDecls>
<taxonomy>
<category auth.uri="http://www.oclc.org/dewey/resources/summaries/default.htm#700" auth="OCLC" xml:id="header.OCLC_DDC"/>
</taxonomy>
</classDecls>
</encodingDesc>
<manifestationList>
<manifestation>
<titleStmt>
<title>Fughette (in Gottes Namen Fahren wir - Dies sind die heil'gen zehn Gebote) for Brass
Quintett
</title>
<respStmt>
<persName role="composer">Johann Christoph Bach</persName>
<persName role="arranger">Michel Rondeau</persName>
</respStmt>
</titleStmt>
<pubStmt>
<identifier type="URI">http://icking-music-archive.org/scores/j.chr.bach/JCBIN-xml.zip</identifier>
<date isodate="2011-10-13"></date>
<respStmt>
<name>Werner Icking Music Archive</name>
</respStmt>
<availability>
<useRestrict>© 2010 - Gatineau,Qc.Ca.</useRestrict>
</availability>
</pubStmt>
<classification>
<termList>
<term class="#header.OCLC_DDC">785.15</term>
</termList>
</classification>
</manifestation>
</manifestationList>
</meiHead>3.8.4. Header Elements and their Relationship to Other Bibliographic Standards
Mapping elements from the MEI metadata header to another descriptive system may help a repository harvest selected data from the MEI file to build a basic catalog record. For this purpose, the following attribute is provided on most elements occurring within meiHead:
The encoding system to which fields are mapped must be specified in @analog. When possible, subfields as well as fields should be specified, e.g., subfields within MARC fields.
3.8.5. Musical Corpora
The term corpus may refer to any collection of musical data, although it is often reserved for collections which have been organized or collected with a particular end in view, generally to illustrate a particular characteristic of, or to demonstrate the variety found in, a group of related texts. The principal distinguishing characteristic of a corpus is that its components have been selected or structured according to some conscious set of design criteria.
In MEI, a corpus is regarded as a composite text because, although each discrete document in a corpus clearly has a claim to be considered as a text in its own right, it is also regarded as a subdivision of some larger object, if only for convenience of analysis. In corpora, the component samples are clearly distinct texts, but the systematic collection, standardized preparation, and common markup of the corpus often make it useful to treat the entire corpus as a unit, too. Corpora share a number of characteristics with other types of composite texts, including anthologies and collections. Most notably, different components of composite texts may exhibit different structural properties, thus potentially requiring elements from different MEI modules.
Aside from these high-level structural differences, and possibly differences of scale, the encoding of language corpora and the encoding of individual texts present identical sets of problems. Therefore, any of the encoding techniques and elements presented in other chapters of these Guidelines may therefore prove relevant to some aspect of corpus encoding and may be used in corpora.
3.8.5.1. Corpus Module Overview
The meiCorpus module defines a single element:
The meiCorpus element is intended for the encoding of corpora, though it may also be useful in encoding any collection of disparate materials. The individual samples in the corpus are encoded as separate mei elements, and the entire corpus is enclosed in an meiCorpus element. Each sample has the usual structure for a mei document, comprising an meiHead followed by a music element. The corpus, too, has a corpus-level meiHead element, in which the corpus as a whole, and encoding practices common to multiple samples may be described. The overall structure of an MEI-conformant corpus is thus:
<meiCorpus>
<meiHead type="corpus">
<!-- metadata for the corpus -->
</meiHead>
<mei>
<meiHead type="text">
<!-- metadata for sample 1 -->
</meiHead>
<music>
<!-- the encoding of sample 1 -->
</music>
</mei>
<mei>
<meiHead type="text">
<!-- metadata for sample 2 -->
</meiHead>
<music>
<!-- the encoding of sample 2 -->
</music>
</mei>
</meiCorpus>This two-level structure allows for metadata to be specified at the corpus level, at the individual text level, or at both. However, metadata which relates to the whole corpus rather than to its individual components should be removed from the individual component metadata and included only in the meiHead element prefixed to the whole.
In some cases, the design of a corpus is reflected in its internal structure. For example, a corpus of musical incipits might be arranged to combine all compositions of one type (symphonies, songs, chamber music, etc.) into some higher-level grouping, possibly with sub-groups for date of publication, instrumentation, key, etc. The meiCorpus element provides no support for reflecting such internal structure in the markup: it treats the corpus as an undifferentiated series of components, each tagged with an mei element.
If it is essential to reflect the organization of a corpus into sub-components, then the members of the corpus should be encoded as composite texts instead, using the group element described section Music Element. The mechanisms for corpus characterization described in this chapter, however, are designed to reduce the need to do this. Useful groupings of components may easily be expressed using the classification and identification elements described in section Classification, and those for associating declarations with corpus components described in section Associating Metadata and Data. These mechanisms also allow several different methods of text grouping to co-exist, each to be used as needed at different times. This helps minimize the danger of cross-classification and mis-classification of samples, and helps improve the flexibility with which parts of a corpus may be characterized for different applications.
All composite texts share the characteristic that their different component texts may be of structurally similar or dissimilar types. If all component texts may all be encoded using the same module, then no problem arises. If however they require different modules, then the various modules must all be included in the schema.
3.8.5.2. Combining Corpus and Text Headers
An MEI-conformant document may have more than one header only in the case of a TEI corpus, which must have a header in its own right, as well as the obligatory header for each text. Every element specified in a corpus-header is understood as if it appeared within every text header in the corpus. An element specified in a text header but not in the corpus header supplements the specification for that text alone. If any element is specified in both corpus and text headers, the corpus header element is over-ridden for that text alone.
The titleStmt for a corpus text is understood to be prefixed by the titleStmt given in the corpus header. All other optional elements of the fileDesc should be omitted from an individual corpus text header unless they differ from those specified in the corpus header. All other header elements behave identically, in the manner documented in chapter . This makes it possible to state information which is common to the whole of the corpus in the corpus header, while still allowing for individual texts to vary from this common metadata.
For example, the following markup shows the structure of a corpus consisting of three texts, the first and last of which share the same encoding description. The second one has its own encoding description.
<meiCorpus>
<meiHead>
<fileDesc>
<!-- corpus file description-->
</fileDesc>
<encodingDesc>
<!-- default encoding description -->
</encodingDesc>
<revisionDesc>
<!-- corpus revision description -->
</revisionDesc>
</meiHead>
<mei>
<meiHead>
<fileDesc>
<!-- file description for this corpus text -->
</fileDesc>
</meiHead>
<music>
<!-- first corpus text -->
</music>
</mei>
<mei>
<meiHead>
<fileDesc>
<!-- file description for this corpus text -->
</fileDesc>
<encodingDesc>
<!-- encoding description for this corpus text, over-riding the default -->
</encodingDesc>
</meiHead>
<music>
<!-- second corpus text -->
</music>
</mei>
<mei>
<meiHead>
<fileDesc>
<!-- file description for third corpus text -->
</fileDesc>
</meiHead>
<music>
<!-- third corpus text -->
</music>
</mei>
</meiCorpus>3.8.5.3. Recommendations for the Encoding of Large Corpora
These Guidelines include proposals for the identification and encoding of a far greater variety of textual features and characteristics than is likely to be either feasible or desirable in any one corpus, however large and ambitious. For most large-scale corpus projects, it will therefore be necessary to determine a subset of recommended elements appropriate to the anticipated needs of the project; these mechanisms include the ability to exclude selected element types, add new element types, and change the names of existing elements.
Because of the high cost of identifying and encoding many textual features, and the difficulty in ensuring consistent practice across very large corpora, encoders may find it convenient to divide the set of elements to be encoded into the following four categories:
required: texts included within the corpus will always encode textual features in this category, should they exist in the text
recommended: textual features in this category will be encoded wherever economically and practically feasible; where present but not encoded, a note in the header should be made.
optional: textual features in this category may or may not be encoded; no conclusion about the absence of such features can be inferred from the absence of the corresponding element in a given text.
proscribed: textual features in this category are deliberately not encoded; they may be transcribed as unmarked up text, or represented as gap elements, or silently omitted, as appropriate.